13 - Spring Data JPA - Definición de entidades
Hemos dicho en el concepto anterior que Spring Data JPA es un módulo del framework Spring que facilita el trabajo con bases de datos relacionales (MySQL, PostgreSQL, SqlServer etc.) utilizando la API de persistencia de Java (JPA - Java Persistence API).
Spring Data JPA simplifica el desarrollo de aplicaciones que acceden a datos relacionales al proporcionar una capa de abstracción sobre JPA, lo que reduce la cantidad de código repetitivo que necesitamos escribir.
Definición de entidades
Las definiciones de entidades JPA son clases Java que representan tablas en una base de datos relacional. Se utilizan para mapear objetos Java a tablas de bases de datos, lo que permite a los desarrolladores trabajar con datos relacionales utilizando objetos Java.
En el concepto anterior definimos la entidad 'Chiste':
package com.example.demo.model;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
@Entity
public class Chiste {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
private String texto;
private String autor;
public Chiste() {
}
public Chiste(int id, String texto, String autor) {
this.id = id;
this.texto = texto;
this.autor = autor;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTexto() {
return texto;
}
public void setTexto(String texto) {
this.texto = texto;
}
public String getAutor() {
return autor;
}
public void setAutor(String autor) {
this.autor = autor;
}
}
Las definiciones de entidades JPA se definen con la anotación @Entity, que indica a JPA que la clase es una entidad persistente. En el concepto anterior solo vimos las anotaciones: @Entity, @Id y @GeneratedValue
Para situaciones muy sencillas podemos utilizar pocas anotaciones, pero disponemos de otras anotaciones para especificar características de la tabla de base de datos que se debe crear y mantener.
Anotaciones principales de las entidades
-
@Entity: Marca la clase como una entidad JPA, lo que significa que será mapeada a una tabla en la base de datos (es una anotación obligatoria)
-
@Table Opcionalmente, se puede usar para especificar el nombre de la tabla y otros detalles de la tabla en la base de datos.
@Entity @Table(name = "empleados") public class Empleado {Si no disponemos la anotación @Table luego la tabla se crea con el nombre 'empleado'. Es una anotación opcional.
-
@Id Marca el atributo como la clave primaria de la entidad.
-
@GeneratedValue Opcionalmente, se puede usar junto con la anotación @Id para especificar cómo se generará el valor de la clave primaria.
-
@Column Permite personalizar el mapeo entre el atributo de la clase y la columna en la tabla de la base de datos.
Si queremos que la columna en la tabla se llame 'mail' y que su longitud sea 70 caracteres:
@Column(name = "mail", length = 70) private String email;
Cuando no hacemos la anotación @Column, se encarga Spring Data JPA de utilizar como nombre de campo el atributo de la clase, lo mismo con la longitud.
-
@Transient Marca un atributo de la clase como no persistente, lo que significa que no se mapeará a una columna en la tabla de la base de datos.
-
@Temporal Se utiliza para mapear atributos de fecha y hora a tipos de datos temporales en la base de datos.
-
@Lob Se utiliza para mapear atributos grandes de objetos binarios a tipos de datos LOB (Large Object) en la base de datos.
Problema
Vamos a crear una aplicación y definir una entidad que represente a datos de un 'usuario'.
-
Creamos el proyecto llamado: proyecto008. Agregando las dependencias de Spring Data JPA, MySQL Driver y Spring Web.
-
Ahora configuramos el acceso a la base de datos 'bd1' en el archivo 'application.properties':
spring.application.name=proyecto008 spring.datasource.url=jdbc:mysql://localhost:3306/bd1?useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.jpa.hibernate.ddl-auto=update
-
Creamos la carpeta model y dentro la clase 'Usuario'.
package com.example.demo.model; import jakarta.persistence.Column; import jakarta.persistence.Entity; import jakarta.persistence.GeneratedValue; import jakarta.persistence.GenerationType; import jakarta.persistence.Id; import jakarta.persistence.Table; @Entity @Table(name = "usuarios") public class Usuario { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "nombre", nullable = false, unique = true, length = 50) private String nombreUsuario; @Column(name = "contrasena", nullable = false, length = 50) private String contrasena; @Column(name = "correo", unique = true, length = 70) private String correoElectronico; public Usuario() { } public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getNombreUsuario() { return nombreUsuario; } public void setNombreUsuario(String nombreUsuario) { this.nombreUsuario = nombreUsuario; } public String getContrasena() { return contrasena; } public void setContrasena(String contrasena) { this.contrasena = contrasena; } public String getCorreoElectronico() { return correoElectronico; } public void setCorreoElectronico(String correoElectronico) { this.correoElectronico = correoElectronico; } }
Si ahora ejecutamos nuestra aplicación, podemos ingresar inmediatamente a Workbench y verificar que se ha creado una tabla llamada 'usuarios' con los campos y tipos especificados:
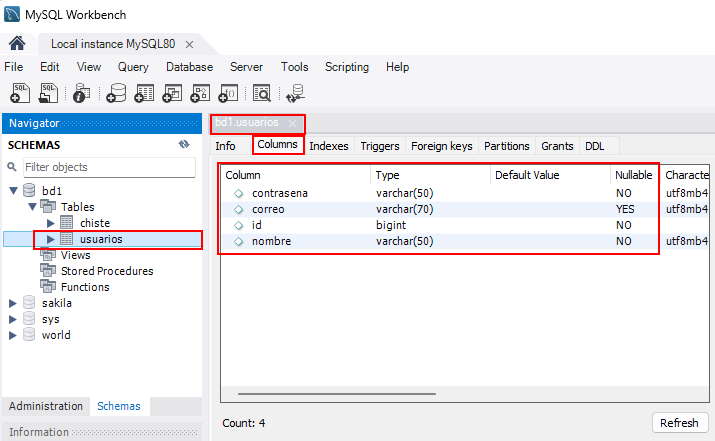
Los atributos nombreUsuario, contrasena y correoElectronico de la clase de Cliente representan las columnas nombre, contrasena y correo en la tabla de la base de datos 'usuarios'.
Hemos dicho que la anotación @Column en JPA se utiliza para personalizar el mapeo entre un atributo de una entidad y la columna correspondiente en la tabla de la base de datos. Esta anotación proporciona varios parámetros que permiten especificar diferentes aspectos del mapeo. Aquí están los parámetros más comunes de la anotación @Column:
name : Especifica el nombre de la columna en la tabla de la base de datos. Por defecto, el nombre de la columna es el nombre del atributo en la clase.
-
nullable: Indica si el valor del atributo puede ser nulo en la base de datos. El valor por defecto es true, lo que significa que el atributo puede ser nulo.
-
unique: Indica si los valores en la columna deben ser únicos en la tabla. El valor por defecto es false.
-
length: Especifica la longitud máxima de la columna. Este parámetro es relevante para atributos de tipo String. El valor por defecto depende del proveedor de persistencia.
-
precision: Especifica el número total de dígitos que puede contener una columna de tipo numérico. Este parámetro es relevante para atributos de tipo BigDecimal o BigInteger.
-
scale: Especifica el número de dígitos a la derecha del punto decimal en una columna de tipo numérico. Este parámetro es relevante para atributos de tipo BigDecimal.
-
columnDefinition: Permite especificar una definición SQL personalizada para la columna en la base de datos. Esto puede ser útil para especificar tipos de datos específicos de la base de datos o restricciones adicionales.
-
insertable: Indica si el atributo debe ser incluido en las operaciones de inserción. El valor por defecto es true.
-
updatable: Indica si el atributo debe ser incluido en las operaciones de actualización. El valor por defecto es true.
Ver los comandos SQL en la consola de la aplicación
Debemos agregar la siguiente configuración en el archivo application.properties:
spring.application.name=proyecto008 spring.datasource.url=jdbc:mysql://localhost:3306/bd1?useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.jpa.hibernate.ddl-auto=update spring.jpa.show-sql=true logging.level.org.hibernate.SQL=debug
Vamos a borrar desde la aplicacion Workbench en forma manual la tabla 'usuarios', seguidamente volvemos a ejecutar nuestra aplicación y podremos ver que en la consola aparece el comando SQL que ejecutó MySQL:
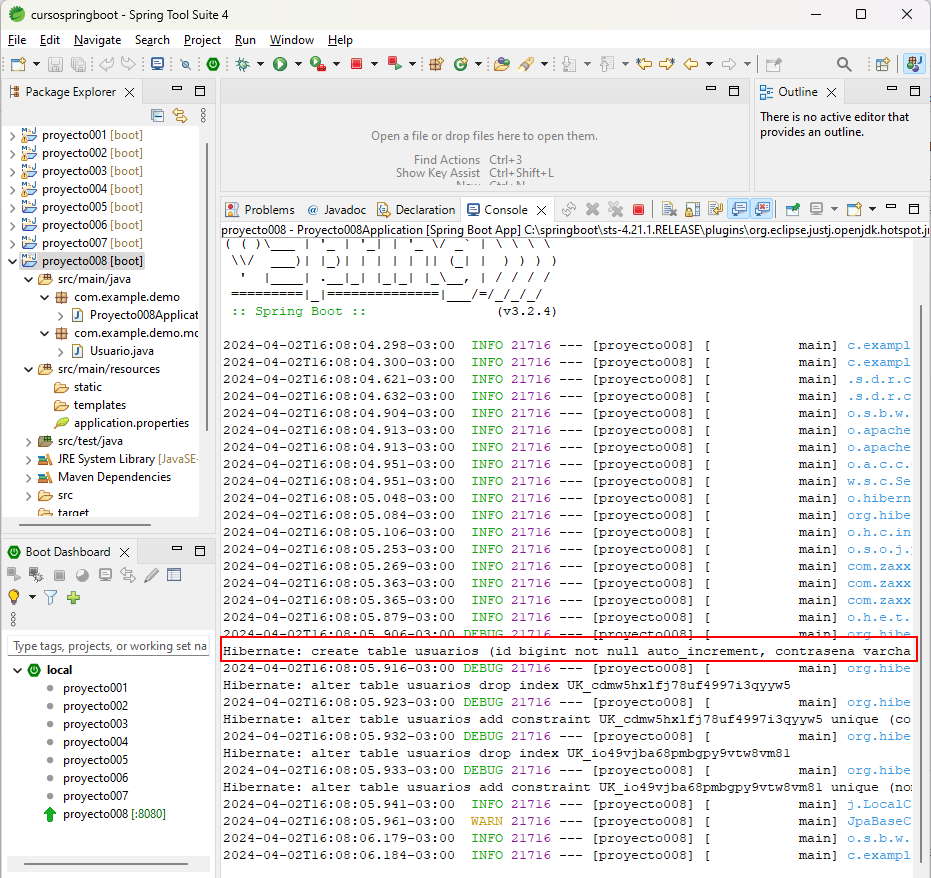
Esta información nos puede ser útil si no queremos ingresar a Workbench para ver la estructura de la tabla. Como podemos ver Spring Boot y en particular Spring Data JPA nos facilita la administración de todas las entidades y su mapeo con las tablas de la base de datos.
Si detenemos y lanzamos nuestra aplicación veremos que no se crea nuevamente la tabla 'usuarios'. En el caso que necesitemos que se vuelva a crear cada vez que lanzamos la aplicación debemos modificar del archivo application.properties la propiedad:
spring.jpa.hibernate.ddl-auto=create
Tener cuidado que cada vez que ahora se lance la aplicación se borran las tablas aunque tengan datos y se vuelven a crear.
Valores posibles de la propiedad spring.jpa.hibernate.ddl-auto
La propiedad spring.jpa.hibernate.ddl-auto es una configuración clave en aplicaciones Spring Boot que utilizan JPA (Java Persistence API) y Hibernate como proveedor de persistencia. Esta propiedad determina cómo Hibernate manejará el esquema de la base de datos en relación con las entidades JPA en la aplicación durante la fase de arranque.
-
update Hibernate actualizará automáticamente el esquema de la base de datos para que coincida con las entidades JPA definidas en la aplicación durante la fase de arranque. Esto puede implicar la creación de nuevas tablas, la modificación de tablas existentes y la eliminación de tablas obsoletas. Sin embargo, Hibernate intentará preservar los datos existentes en la base de datos tanto como sea posible.
-
create Hibernate eliminará y volverá a crear el esquema de la base de datos desde cero en cada arranque de la aplicación. Esto implica la eliminación de todas las tablas existentes y la creación de nuevas tablas según las definiciones de las entidades JPA. Esta opción es adecuada para desarrollo y pruebas, pero no se recomienda en entornos de producción debido al riesgo de pérdida de datos.
-
none Esta configuración deshabilita completamente la creación automática de tablas por parte de Hibernate. No se realizarán cambios en la estructura de la base de datos. Esta opción es adecuada para ambientes de producción donde el esquema de la base de datos ya está establecido y se espera que permanezca inalterado.
-
validate Hibernate valida la estructura de la base de datos con respecto a las entidades JPA definidas en la aplicación durante la inicialización, pero no realiza cambios en la base de datos. Si la estructura de la base de datos no coincide con las entidades definidas, se lanzará una excepción.