13 - Problema resuelto: Comparador de rendimiento - threading vs multiprocessing vs asyncio
Objetivo: ejecutar el mismo conjunto de tareas con threading, multiprocessing y asyncio, midiendo cómo se comportan en 100 tareas I/O-bound (simuladas con sleep) y 100 tareas CPU-bound (cálculo de primos).
Se evalúa el entendimiento práctico del GIL, la medición rigurosa y la interpretación de ventajas/desventajas reales.
13.1 Descripción
Los tres modelos ejecutan el mismo trabajo con diferente semántica de concurrencia. El GIL impide que hilos escalen en CPU-bound, pero no afecta tareas I/O-bound. Los procesos eluden el GIL y el event loop de asyncio brilla en espera de red/temporizadores.
13.2 Diseño de la prueba
- I/O-bound: 100 tareas que duermen 50 ms. Se mide el tiempo total con hilos, procesos y corrutinas (
asyncio.sleep). - CPU-bound: 50 tareas que cuentan primos en un rango más pesado (10 000 a 50 000) para que el costo CPU domine sobre el overhead de procesos.
- Gráfico: se genera un PNG opcional con
matplotlibpara comparar barras.
13.3 Pasos
- Definir tareas sintéticas I/O-bound y CPU-bound.
- Instrumentar funciones que corran las tareas con cada modelo y devolver tiempos.
- Repetir mediciones en un mismo script y mostrar tabla/tiempos.
- Opcional: guardar gráfico de barras en
grafico_rendimiento.png.
13.4 Codificación
Guarda el siguiente script como comparador.py. Requiere solo la biblioteca estándar; el gráfico usa matplotlib si está instalado (pip install matplotlib).
import asyncio
import concurrent.futures as futures
import math
import os
import time
from typing import Awaitable, Callable, Iterable, List, Tuple
TAREAS_IO = 100
TAREAS_CPU = 50
SLEEP_S = 0.05 # 50 ms para simular I/O
MAX_CPU = os.cpu_count() or 4
RANGO_PRIMOS = range(10_000, 50_000)
def io_sleep(_):
time.sleep(SLEEP_S)
return True
def es_primo(n: int) -> bool:
if n < 2:
return False
if n % 2 == 0:
return n == 2
limite = int(math.sqrt(n)) + 1
for i in range(3, limite, 2):
if n % i == 0:
return False
return True
def cpu_primos(rango: Iterable[int]) -> int:
return sum(1 for n in rango if es_primo(n))
def medir(nombre: str, fn: Callable[[], None]) -> Tuple[str, float]:
inicio = time.perf_counter()
fn()
return nombre, time.perf_counter() - inicio
def medir_async(nombre: str, coro: Callable[[], Awaitable[None]]) -> Tuple[str, float]:
inicio = time.perf_counter()
asyncio.run(coro())
return nombre, time.perf_counter() - inicio
def medir_io_threading():
with futures.ThreadPoolExecutor(max_workers=20) as ex:
list(ex.map(io_sleep, range(TAREAS_IO)))
def medir_io_multiprocessing():
with futures.ProcessPoolExecutor(max_workers=MAX_CPU) as ex:
list(ex.map(io_sleep, range(TAREAS_IO)))
async def medir_io_asyncio():
await asyncio.gather(*[asyncio.sleep(SLEEP_S) for _ in range(TAREAS_IO)])
def medir_cpu_threading():
with futures.ThreadPoolExecutor(max_workers=MAX_CPU) as ex:
list(ex.map(cpu_primos, [RANGO_PRIMOS] * TAREAS_CPU))
def medir_cpu_multiprocessing():
with futures.ProcessPoolExecutor(max_workers=MAX_CPU) as ex:
list(ex.map(cpu_primos, [RANGO_PRIMOS] * TAREAS_CPU))
async def medir_cpu_asyncio():
loop = asyncio.get_running_loop()
# Usa hilos por defecto: el GIL impide paralelizar CPU, solo se interlelan.
with futures.ThreadPoolExecutor(max_workers=MAX_CPU) as pool:
tareas = [loop.run_in_executor(pool, cpu_primos, RANGO_PRIMOS) for _ in range(TAREAS_CPU)]
await asyncio.gather(*tareas)
def ejecutar_pruebas() -> List[Tuple[str, float]]:
resultados = []
resultados.append(medir("io_threading", medir_io_threading))
resultados.append(medir("io_multiprocessing", medir_io_multiprocessing))
resultados.append(medir_async("io_asyncio", medir_io_asyncio))
resultados.append(medir("cpu_threading", medir_cpu_threading))
resultados.append(medir("cpu_multiprocessing", medir_cpu_multiprocessing))
resultados.append(medir_async("cpu_asyncio_threads", medir_cpu_asyncio))
return resultados
def imprimir_tabla(resultados: List[Tuple[str, float]]):
print("\n=== Resultados (segundos) ===")
for nombre, t in resultados:
print(f"{nombre:22s} -> {t:0.3f}s")
def graficar(resultados: List[Tuple[str, float]], ruta: str = "grafico_rendimiento.png"):
try:
import matplotlib.pyplot as plt
except ImportError:
print("Instala matplotlib para generar el gr\u00e1fico: pip install matplotlib")
return
etiquetas = [r[0] for r in resultados]
tiempos = [r[1] for r in resultados]
colores = ["#4caf50" if "io" in e else "#ff9800" for e in etiquetas]
plt.figure(figsize=(10, 5))
plt.bar(etiquetas, tiempos, color=colores)
plt.xticks(rotation=25, ha="right")
plt.ylabel("segundos (menos es mejor)")
plt.title("Threading vs Multiprocessing vs Asyncio")
plt.tight_layout()
plt.savefig(ruta, dpi=120)
print(f"Gr\u00e1fico guardado en {ruta}")
if __name__ == "__main__":
resultados = ejecutar_pruebas()
imprimir_tabla(resultados)
graficar(resultados)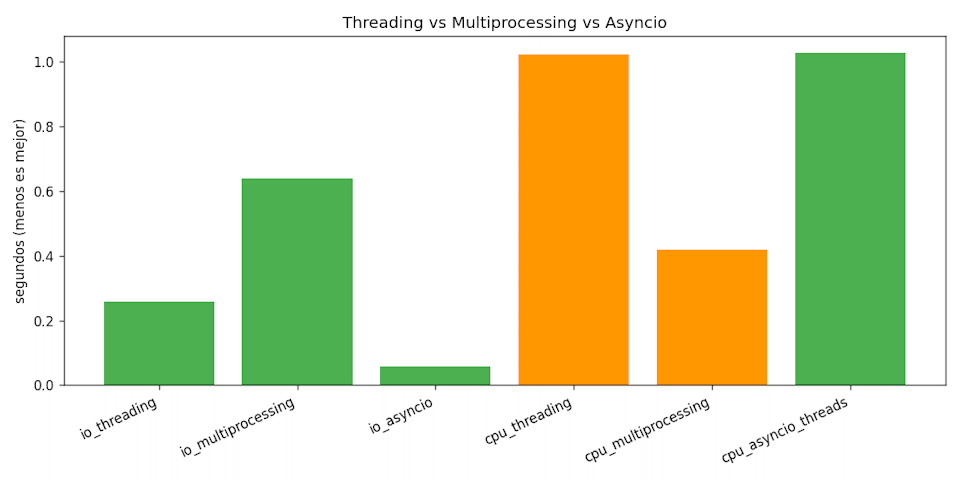
Puntos clave:
- GIL: en
cpu_threadingycpu_asyncio_threadsno hay paralelismo real; el tiempo suele parecerse al secuencial. - Procesos:
cpu_multiprocessingescala al número de núcleos; con el rango 10 000-50 000 el costo de spawn se amortiza y debería ser menor que hilos. - I/O:
io_asyncioyio_threadingcompletan rápido al solapar esperas;io_multiprocessingpaga overhead sin ganar. - Gráfico opcional: si
matplotlibestá instalado, se generagrafico_rendimiento.png; de lo contrario se imprime la tabla.
13.5 Interpretación de resultados
- I/O-bound: el loop de eventos (
asyncio) es el más eficiente en número de hilos;threadingtambién escala aceptablemente; procesos son innecesarios. - CPU-bound: procesos ganan porque cada proceso tiene su propio GIL. Hilos y
asynciocon hilos solo intercalan ejecución. - Impacto del GIL: el GIL sólo afecta cuando varias tareas CPU-bound quieren correr a la vez en hilos del mismo proceso; no afecta esperas de red o temporizadores.
- Elección: para CPU usa procesos; para I/O masivo usa
asyncioo hilos; mezcla modelos cuando el trabajo es mixto.
13.6 Qué se evalúa
- Medición seria: mismo número de tareas y carga comparable; medir con
perf_counter. - Comprensión: interpretar el rol del GIL y por qué procesos escalan en CPU.
- Ventajas y desventajas: costos de arranque de procesos, simplicidad de hilos, eficiencia de
asyncioen I/O.