2 - Concurrencia con threading
En este tema se usa el módulo threading para crear hilos nativos, sincronizarlos y evitar errores comunes. Se centra en tareas I/O-bound donde el GIL no es un obstáculo y los hilos permiten solapar esperas.
Sigue siendo código CPU cooperativo: Python alterna hilos mientras alguno espera datos o libera el GIL en llamadas bloqueantes.
2.1 El módulo threading: visión general
- Hilos como objetos: cada
threading.Threadrepresenta una hebra con estado (viva, terminada) y atributos comonameodaemon. - target, args, kwargs: definen la función que ejecutará el hilo y los argumentos posicionales o nombrados.
- start() y join():
start()lanza el hilo;join()espera su finalización. Un hilo solo se puede iniciar una vez. - Tiempo de vida: un hilo termina cuando la función objetivo retorna o lanza una excepción no capturada. Si es
daemon=True, no bloquea la salida del proceso.
2.2 Creación manual de hilos
Existen dos patrones básicos: basados en función y basados en clase.
Usa nombres descriptivos para depurar (name="worker-1") y marca hilos como daemon si deben cerrarse cuando el proceso principal termina.
import threading
def trabajador(nombre):
print(f"[funcion] Hola desde {nombre}")
class Trabajador(threading.Thread):
def __init__(self, nombre):
super().__init__(name=nombre)
self.nombre = nombre
def run(self):
print(f"[clase] Hola desde {self.nombre}")
if __name__ == "__main__":
t1 = threading.Thread(target=trabajador, args=("hilo-1",))
t2 = Trabajador("hilo-2")
t1.start()
t2.start()
t1.join()
t2.join()
print("Listo")Ambos hilos se ejecutan de forma concurrente en el mismo proceso (sin paralelismo real de CPU por el GIL). El enfoque por función es más liviano; el enfoque por clase es útil si se necesita estado interno o sobreescribir run().
2.3 Sincronización con threading
- Lock (mutex): exclusión mutua simple. Se adquiere con
lock.acquire()o el contextowith lock:. - RLock: permite que el mismo hilo adquiera el candado varias veces sin bloquearse (recursivo).
- Semaphore: controla acceso a un recurso contable (n disponibles). Útil para limitar conexiones simultáneas.
- Event: señal binaria (activado/no activado) para coordinar inicios o paradas.
- Condition: combina un Lock con una cola de espera para notificar cambios de estado entre productores y consumidores.
2.4 Problemas clásicos al usar threads
- Race conditions: lectura/escritura concurrente sin protección lleva a estados inconsistentes.
- Deadlocks: dos o más hilos esperan recursos que nunca se liberan (adquisición circular de locks).
- Context switching excesivo: demasiados hilos generan sobrecosto del scheduler y cachés frías.
- Recursos compartidos mal gestionados: colecciones mutables sin sincronización o uso indebido de variables globales.
2.5 Aplicación: Descargador concurrente de URLs (I/O-bound)
El siguiente programa compara una descarga secuencial vs otra concurrente con hilos. Usa un Lock para escribir en el log de forma ordenada y urllib.request para evitar dependencias externas.
La versión concurrente reduce el tiempo total siempre que la mayor parte sea espera de red; si los sitios responden rápido, el beneficio puede ser menor.
import threading
import time
from urllib import request, error
URLS = [
"https://www.example.com/",
"https://www.python.org/",
"https://www.infobae.com/",
]
def descargar(url, log, lock):
inicio = time.perf_counter()
try:
with request.urlopen(url, timeout=5) as resp:
resp.read(1024)
estado = "ok"
except error.URLError as exc:
estado = f"error: {exc}"
duracion = time.perf_counter() - inicio
with lock:
log.append((url, estado, duracion))
def secuencial(urls):
log = []
lock = threading.Lock()
for url in urls:
descargar(url, log, lock)
return log
def concurrente(urls):
log = []
lock = threading.Lock()
hilos = []
for url in urls:
t = threading.Thread(target=descargar, args=(url, log, lock))
t.start()
hilos.append(t)
for t in hilos:
t.join()
return log
if __name__ == "__main__":
inicio = time.perf_counter()
log_seq = secuencial(URLS)
t_seq = time.perf_counter() - inicio
inicio = time.perf_counter()
log_conc = concurrente(URLS)
t_conc = time.perf_counter() - inicio
print("--- Secuencial ---")
for entrada in log_seq:
print(entrada)
print(f"Total: {t_seq:.2f}s")
print("--- Concurrente ---")
for entrada in log_conc:
print(entrada)
print(f"Total: {t_conc:.2f}s")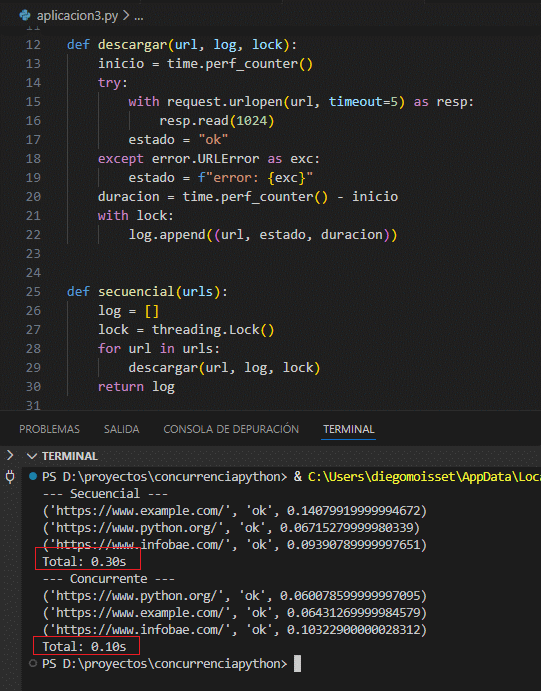
En un entorno con latencias reales, la versión concurrente suele ser significativamente más rápida al solapar las esperas de red. El Lock evita que las escrituras en log se mezclen.
Puedes aumentar max_workers si el ancho de banda lo permite, pero evita crear cientos de hilos en Windows o entornos limitados.