4 - Concurrencia con multiprocessing
El módulo multiprocessing permite paralelismo real usando procesos separados, cada uno con su propio intérprete y sin compartir el GIL. Es la opción recomendada para cargas CPU-bound en máquinas con varios núcleos.
4.1 Por qué multiprocessing evita el GIL
- Procesos independientes: cada proceso ejecuta su propio intérprete CPython y su propio GIL, sin interferir.
- Paralelismo real: el sistema operativo puede ejecutar procesos en núcleos distintos al mismo tiempo.
4.2 Procesos: creación y gestión
- Process(): instancia un proceso con
target,argsykwargs, similar a los hilos. - start() y join():
start()lanza el proceso hijo;join()espera su finalización. - Paso de argumentos: los parámetros se serializan (pickle) al crear el proceso; evita objetos no serializables.
- Retorno de datos: usa colas, pipes o valores compartidos para devolver resultados al padre; no se comparte memoria por defecto.
4.3 Sincronización en multiprocessing
Los primitivos son similares a threading pero se implementan con IPC (inter-proces communication).
- Locks y RLocks: para exclusión mutua sobre recursos compartidos (memoria compartida, archivos).
- Semaphores: controlan recursos contables.
- Events: señales entre procesos.
- Conditions: combinan lock + cola de espera para coordinar cambios de estado.
4.4 Comunicación entre procesos
- Pipes: canales unidireccionales o bidireccionales ligeros.
- Queues (multiprocessing.Queue): basadas en pipes + locks; permiten pasar objetos picklables de forma segura.
- Diferencia con queue.Queue:
queue.Queuees para hilos dentro del mismo proceso;multiprocessing.Queueusa IPC y funciona entre procesos.
4.5 Problemas típicos
- Costo de crear procesos: más lento y pesado que crear hilos; usa pools para amortizar.
- Serialización (pickle): funciones u objetos no picklables fallarán; evita lambdas y cierres no serializables.
- Objetos grandes: pasar grandes blobs por colas es costoso; usa memoria compartida si necesitas alto volumen.
- Windows vs Linux: en Windows el método es
spawn(reimporta el módulo); en Linux puede usarfork, que es más rápido pero hereda estado. Protege tu código conif __name__ == "__main__":.
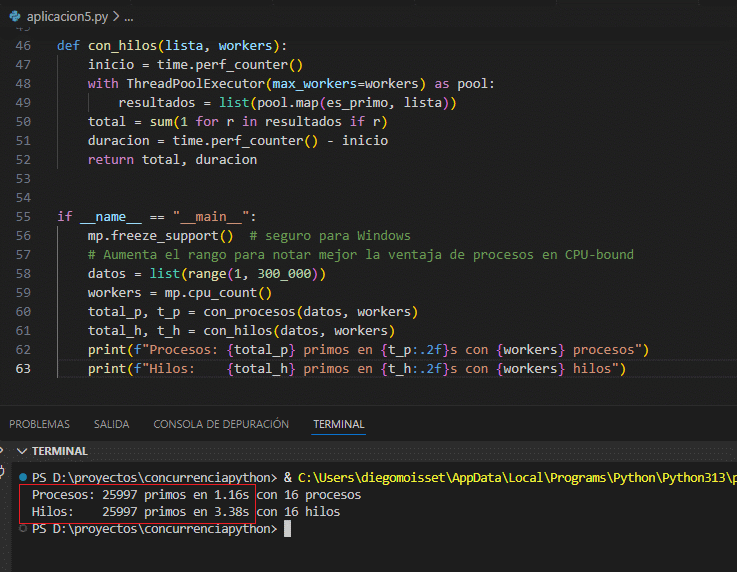
4.6 Aplicación: Procesador paralelo de listas (CPU-bound)
Este ejemplo divide una lista grande en partes, reparte el trabajo entre procesos y compara el tiempo contra una versión con hilos. Se usa multiprocessing.Queue para recolectar resultados.
import math
import multiprocessing as mp
import time
from concurrent.futures import ThreadPoolExecutor
def es_primo(n: int) -> bool:
if n < 2:
return False
if n % 2 == 0:
return n == 2
limite = int(math.sqrt(n)) + 1
for i in range(3, limite, 2):
if n % i == 0:
return False
return True
def contar_primos(numeros, salida):
cuenta = sum(1 for n in numeros if es_primo(n))
salida.put(cuenta)
def dividir(lista, partes):
tam = len(lista)
paso = (tam + partes - 1) // partes
for i in range(0, tam, paso):
yield lista[i : i + paso]
def con_procesos(lista, workers):
salida = mp.Queue()
procesos = []
inicio = time.perf_counter()
for chunk in dividir(lista, workers):
p = mp.Process(target=contar_primos, args=(chunk, salida))
p.start()
procesos.append(p)
for p in procesos:
p.join()
total = sum(salida.get() for _ in procesos)
duracion = time.perf_counter() - inicio
return total, duracion
def con_hilos(lista, workers):
inicio = time.perf_counter()
with ThreadPoolExecutor(max_workers=workers) as pool:
resultados = list(pool.map(es_primo, lista))
total = sum(1 for r in resultados if r)
duracion = time.perf_counter() - inicio
return total, duracion
if __name__ == "__main__":
mp.freeze_support() # seguro para Windows
# Rango amplio para notar mejor la ventaja de procesos en CPU-bound
datos = list(range(1, 300_000))
workers = mp.cpu_count()
total_p, t_p = con_procesos(datos, workers)
total_h, t_h = con_hilos(datos, workers)
print(f"Procesos: {total_p} primos en {t_p:.2f}s con {workers} procesos")
print(f"Hilos: {total_h} primos en {t_h:.2f}s con {workers} hilos")La versión con procesos suele ganar en cargas realmente pesadas porque cada proceso usa un núcleo sin compartir el GIL; pero si el trabajo por elemento es moderado o la lista es chica, el overhead de crear procesos y mover datos puede hacer que los hilos resulten más rápidos (como verás en algunas mediciones). Con un rango amplio como range(1, 300_000) o cálculos más costosos se aprecia mejor la ventaja de multiprocessing; también ayuda usar un Pool que reutilice procesos. Protege siempre el punto de entrada con if __name__ == "__main__": para evitar ejecuciones recursivas en Windows.