5 - Encadenamiento (Separate Chaining)
Concepto general
El encadenamiento resuelve colisiones almacenando, en cada bucket del array, una estructura enlazada (usualmente una lista). Cuando varias claves apuntan al mismo índice, se agregan como nodos dentro de la lista de ese bucket.
5.1 Concepto básico
Cada bucket apunta al inicio de una lista de pares clave-valor. Insertar implica agregar un nodo en esa lista; buscar y eliminar consisten en recorrerla hasta hallar la clave.
5.2 Lista enlazada en cada bucket
Una lista simple por bucket mantiene el orden de inserción y simplifica altas y bajas sin reubicar otros elementos.
5.3 Representación del bucket en Python
class HashNode:
def __init__(self, clave, valor, sig=None):
self.clave = clave
self.valor = valor
self.sig = sig
class HashTable:
def __init__(self, capacidad):
self.capacidad = capacidad
self.cantidad = 0
self.buckets = [None] * capacidadCada entrada del array buckets almacena el puntero al primer nodo de la lista correspondiente. El campo cantidad facilita calcular el factor de carga.
5.4 Inserción con encadenamiento
def hash_cadena(clave, cap):
h = 5381
for caracter in clave:
h = ((h << 5) + h) + ord(caracter) # djb2
return h % cap
def hash_insertar(tabla, clave, valor):
idx = hash_cadena(clave, tabla.capacidad)
nodo = tabla.buckets[idx]
while nodo is not None:
if nodo.clave == clave:
nodo.valor = valor
return True
nodo = nodo.sig
nuevo = HashNode(clave, valor, tabla.buckets[idx])
tabla.buckets[idx] = nuevo
tabla.cantidad += 1
return TrueSe recorre la lista del bucket buscando la clave; si ya existe se actualiza el valor, de lo contrario se agrega un nodo al inicio.
5.5 Búsqueda
def hash_buscar(tabla, clave):
idx = hash_cadena(clave, tabla.capacidad)
nodo = tabla.buckets[idx]
while nodo is not None:
if nodo.clave == clave:
return nodo
nodo = nodo.sig
return NoneLa búsqueda queda acotada a la longitud de la lista dentro del bucket, en lugar de revisar toda la tabla.
5.6 Eliminación
def hash_eliminar(tabla, clave):
idx = hash_cadena(clave, tabla.capacidad)
actual = tabla.buckets[idx]
anterior = None
while actual is not None:
if actual.clave == clave:
if anterior is None:
tabla.buckets[idx] = actual.sig
else:
anterior.sig = actual.sig
tabla.cantidad -= 1
return True
anterior = actual
actual = actual.sig
return FalseEliminar requiere llevar un puntero previo para ajustar el enlace cuando se quita el nodo objetivo.
5.7 Complejidad temporal
- Inserción: O(1) promedio; O(k) si la lista del bucket tiene k nodos.
- Búsqueda: O(1) promedio; O(k) en el peor caso dentro del bucket.
- Eliminación: O(1) promedio; O(k) con el mismo razonamiento.
La clave para sostener O(1) promedio es mantener el factor de carga bajo y una función hash que disperse bien.
5.8 Ventajas y desventajas
- Ventajas: borrados simples, implementación directa con listas, tolera factores de carga más altos que el open addressing.
- Desventajas: usa memoria extra por nodos, peor localidad de cache, el peor caso puede crecer si las listas se alargan.
5.9 Problemas más comunes
- Listas largas: indican falta de rehashing o función hash pobre; revisar factor de carga.
- Fugas de memoria: olvidar liberar nodos al rehash o al destruir la tabla.
- Claves duplicadas: no actualizar el valor existente puede generar múltiples nodos con la misma clave.
- Uso de cadenas temporales: guardar punteros a buffers que luego se liberan provoca lecturas inválidas; duplicar cadenas si es necesario.
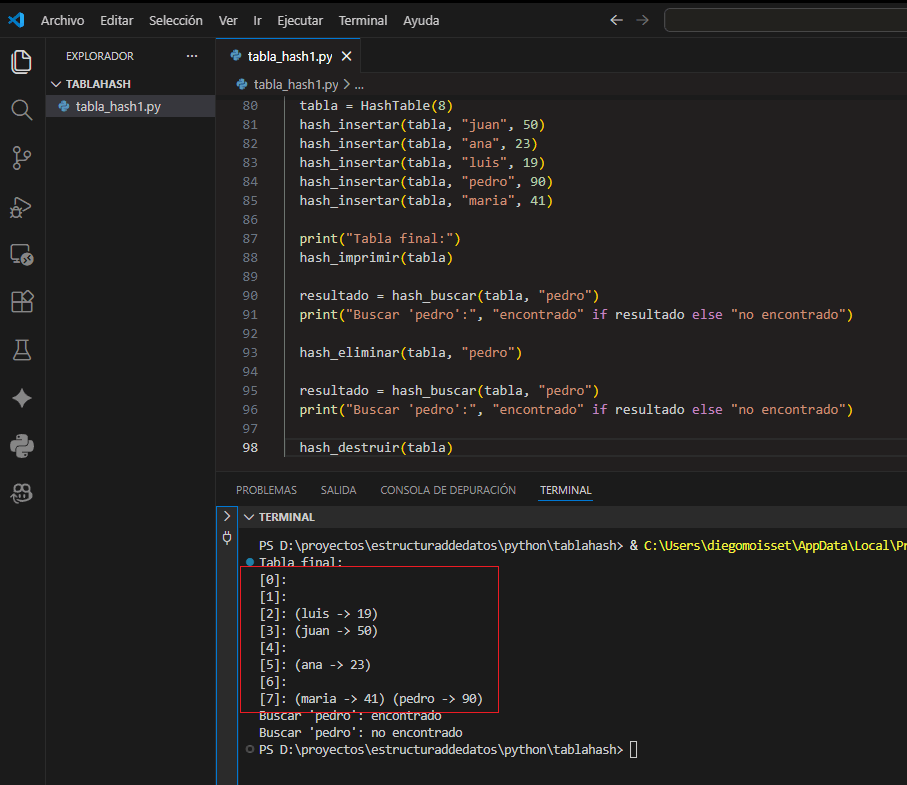
5.10 Ejercicio completo para probar en VSCode
Copia el siguiente programa en main.py y ejecútalo. Inserta, busca y elimina claves usando encadenamiento, y muestra el estado final de la tabla.
La clave de la tabla de hash es el nombre y su valor asociado es la edad de dicha persona.
class HashNode:
def __init__(self, clave, valor, sig=None):
self.clave = clave
self.valor = valor
self.sig = sig
class HashTable:
def __init__(self, capacidad):
self.capacidad = capacidad
self.cantidad = 0
self.buckets = [None] * capacidad
def hash_cadena(clave, cap):
h = 5381
for caracter in clave:
h = ((h << 5) + h) + ord(caracter) # djb2
return h % cap
def hash_insertar(tabla, clave, valor):
idx = hash_cadena(clave, tabla.capacidad)
nodo = tabla.buckets[idx]
while nodo is not None:
if nodo.clave == clave:
nodo.valor = valor
return True
nodo = nodo.sig
nuevo = HashNode(clave, valor, tabla.buckets[idx])
tabla.buckets[idx] = nuevo
tabla.cantidad += 1
return True
def hash_buscar(tabla, clave):
idx = hash_cadena(clave, tabla.capacidad)
nodo = tabla.buckets[idx]
while nodo is not None:
if nodo.clave == clave:
return nodo
nodo = nodo.sig
return None
def hash_eliminar(tabla, clave):
idx = hash_cadena(clave, tabla.capacidad)
actual = tabla.buckets[idx]
anterior = None
while actual is not None:
if actual.clave == clave:
if anterior is None:
tabla.buckets[idx] = actual.sig
else:
anterior.sig = actual.sig
tabla.cantidad -= 1
return True
anterior = actual
actual = actual.sig
return False
def hash_imprimir(tabla):
for i in range(tabla.capacidad):
partes = []
nodo = tabla.buckets[i]
while nodo is not None:
partes.append(f"({nodo.clave} -> {nodo.valor})")
nodo = nodo.sig
print(f"[{i}]: " + " ".join(partes))
def hash_destruir(tabla):
tabla.buckets = []
tabla.cantidad = 0
tabla.capacidad = 0
if __name__ == "__main__":
tabla = HashTable(8)
hash_insertar(tabla, "juan", 50)
hash_insertar(tabla, "ana", 23)
hash_insertar(tabla, "luis", 19)
hash_insertar(tabla, "pedro", 90)
hash_insertar(tabla, "maria", 41)
print("Tabla final:")
hash_imprimir(tabla)
resultado = hash_buscar(tabla, "pedro")
print("Buscar 'pedro':", "encontrado" if resultado else "no encontrado")
hash_eliminar(tabla, "pedro")
resultado = hash_buscar(tabla, "pedro")
print("Buscar 'pedro':", "encontrado" if resultado else "no encontrado")
hash_destruir(tabla)En VSCode, crea un proyecto de Python, reemplaza main.py con el código anterior y ejecuta. Observa cómo las colisiones se guardan en listas dentro de cada bucket.
Animación de inserción en la tabla
Pulsa el botón para ver cómo se insertan juan, ana, luis, pedro y maria usando el hash djb2 sobre 8 buckets. Cada colisión se encadena al frente, igual que en el código en Python.