17. Procesamiento de texto con NLTK
17.1 Introducción
En el tema anterior vimos el panorama general de librerías de NLP en Python y señalamos que NLTK ocupa un lugar especial como biblioteca muy valiosa para aprender fundamentos y experimentar con técnicas clásicas.
Ahora daremos un paso más concreto: veremos cómo pensar el procesamiento de texto con NLTK, qué tipo de herramientas ofrece y por qué sigue siendo una biblioteca tan útil para estudiar los conceptos básicos del área.
En este tema el foco no estará en agotar todos los detalles de su API, sino en entender qué puede hacerse con NLTK y cómo se conecta con los conceptos de preprocesamiento y análisis que ya venimos estudiando.
17.2 ¿Qué es NLTK?
NLTK, sigla de Natural Language Toolkit, es una biblioteca de Python orientada al trabajo con lenguaje natural. Su fortaleza histórica está en ofrecer un conjunto amplio de herramientas clásicas, corpora (colecciones de textos) y utilidades lingüísticas de manera didáctica.
Durante muchos años fue una de las puertas de entrada más importantes al NLP para estudiantes, docentes e investigadores que querían experimentar con texto sin construir todas las herramientas desde cero.
17.3 ¿Por qué sigue siendo importante?
Aunque hoy existen bibliotecas más orientadas a producción o a modelos modernos, NLTK sigue siendo importante porque permite entender con claridad muchos conceptos básicos del procesamiento de texto.
Por ejemplo, es muy útil para trabajar con:
- Tokenización.
- Frecuencias léxicas.
- Stopwords.
- Stemming.
- Lematización básica.
- Corpora de ejemplo.
En otras palabras, NLTK funciona muy bien como laboratorio conceptual de NLP clásico.
17.4 Instalación y recursos descargables
Una particularidad de NLTK es que muchas de sus utilidades dependen de recursos adicionales que se descargan por separado: corpora, tokenizadores, listas de stopwords, léxicos y otros datos lingüísticos.
Esto significa que no siempre alcanza con instalar la biblioteca. También puede ser necesario descargar recursos específicos según lo que se quiera hacer.
Desde el punto de vista didáctico, esto tiene una ventaja: ayuda a entender que muchas herramientas de NLP combinan código con datos lingüísticos auxiliares.
17.5 NLTK como conjunto de módulos
NLTK no debe pensarse como una única función mágica que "hace NLP". Es más bien un ecosistema de módulos orientados a tareas diferentes. Algunos se enfocan en segmentar texto, otros en recursos léxicos, otros en clasificación, otros en corpora o en análisis más específico.
Esto hace que su uso sea muy flexible, pero también que resulte importante saber qué componente usar en cada momento.
17.6 Tokenización con NLTK
Una de las tareas más comunes con NLTK es la tokenización. La biblioteca ofrece herramientas para dividir texto en palabras o en oraciones, lo cual resulta especialmente útil porque tokenizar bien no es tan simple como separar por espacios.
Con NLTK podemos trabajar conceptualmente con:
- Separación en palabras.
- Separación en oraciones.
- Tokenización básica para experimentación.
Esto conecta directamente con los temas anteriores del curso.
17.7 Frecuencias léxicas
Otra tarea muy típica es calcular frecuencias de palabras o tokens. NLTK ofrece estructuras cómodas para contar ocurrencias y explorar cuáles son los términos más comunes en un texto o corpus.
Esto resulta útil para:
- Análisis exploratorio.
- Detección de términos frecuentes.
- Estudio de vocabulario.
- Inspección preliminar de un corpus.
Desde el punto de vista pedagógico, es una forma excelente de conectar teoría con observación concreta de datos textuales.
17.8 Stopwords con NLTK
NLTK incluye listas de stopwords para distintos idiomas. Esto permite experimentar rápidamente con la eliminación de palabras frecuentes y ver cómo cambia la representación del texto.
Sin embargo, tal como vimos en el tema correspondiente, usar stopwords exige criterio. Que NLTK ofrezca una lista no significa que debamos aplicarla automáticamente en cualquier tarea.
17.9 Stemming con NLTK
NLTK también es muy conocido por sus herramientas de stemming. Esto lo vuelve especialmente útil para aprender cómo distintas variantes morfológicas pueden reducirse a raíces aproximadas.
Desde una perspectiva educativa, el stemming en NLTK permite ver con claridad tanto el valor práctico de esta técnica como sus limitaciones.
17.10 Lematización con NLTK
Además del stemming, NLTK ofrece herramientas para lematización. Esto permite comparar ambos enfoques dentro de un mismo entorno de trabajo y observar en la práctica la diferencia entre una reducción heurística y una reducción hacia lemas lingüísticamente más correctos.
Esto es muy valioso para quienes están aprendiendo NLP porque muestra que no todas las técnicas de reducción textual son equivalentes.
17.11 Trabajo con corpora
Una de las grandes fortalezas históricas de NLTK es el acceso a corpora y recursos lingüísticos. La biblioteca facilita experimentar con colecciones de textos ya organizadas, lo que permite practicar análisis, tokenización y frecuencia sin tener que construir todo un dataset desde cero.
Esto resulta especialmente útil en educación, porque permite concentrarse en los conceptos del NLP antes de enfrentarse a problemas más complejos de ingeniería de datos.
17.12 Etiquetado y análisis lingüístico básico
NLTK también ofrece herramientas para tareas de análisis lingüístico como etiquetado gramatical y otras formas de procesamiento clásico. Aunque hoy existan bibliotecas más eficientes para algunas de estas tareas, sigue siendo muy útil para aprender la lógica detrás de ellas.
Esto refuerza una idea importante: NLTK no solo sirve para limpiar texto, sino también para introducir conceptos más estructurados del análisis lingüístico computacional.
17.13 Clasificación y experimentación simple
En NLP clásico, NLTK también puede utilizarse para construir clasificadores sencillos y experimentar con pipelines básicos. No es necesariamente la biblioteca más usada hoy para clasificación en producción, pero sí resulta muy útil para entender cómo se conectan las etapas de preprocesamiento con tareas supervisadas simples.
17.14 ¿Qué tipo de proyectos encajan bien con NLTK?
NLTK encaja especialmente bien en contextos como:
- Aprendizaje y enseñanza de fundamentos.
- Prototipos conceptuales.
- Análisis exploratorio de texto.
- Experimentos con técnicas clásicas.
- Trabajo académico introductorio.
No significa que no pueda usarse en otros contextos, pero su punto fuerte está claramente en el terreno formativo y exploratorio.
17.15 ¿Qué no conviene esperar de NLTK?
También es importante tener expectativas realistas. NLTK no está especialmente orientada a ser la solución más rápida o más moderna para pipelines industriales grandes, ni es la herramienta principal para trabajar con modelos neuronales de última generación.
Su valor principal está en claridad, amplitud de recursos clásicos y facilidad para experimentar con conceptos fundamentales.
17.16 NLTK como puente entre teoría y práctica
Justamente por su enfoque didáctico, NLTK funciona muy bien como puente entre la teoría y la práctica. Permite tomar conceptos que vimos en temas anteriores y aplicarlos sobre texto real de manera relativamente directa.
Por ejemplo, después de estudiar tokenización, stopwords, stemming o lematización, NLTK permite experimentar con todos esos pasos sin demasiada fricción.
17.17 Relación con otras bibliotecas
NLTK no reemplaza a spaCy, scikit-learn o PyTorch. Más bien ocupa un lugar distinto dentro del ecosistema. Puede convivir con otras herramientas según la necesidad.
Por ejemplo:
- NLTK puede servir para explorar y comprender el texto.
- scikit-learn puede usarse después para vectorización y clasificación.
- spaCy puede elegirse cuando se necesite mayor eficiencia en un pipeline lingüístico.
17.18 Flujo conceptual típico con NLTK
Un flujo de trabajo muy común con NLTK podría incluir pasos como:
- Cargar o descargar recursos necesarios.
- Leer un texto o corpus.
- Tokenizar en palabras u oraciones.
- Analizar frecuencias o vocabulario.
- Aplicar stopwords, stemming o lematización.
- Explorar o preparar el resultado para etapas posteriores.
Este flujo es muy adecuado para practicar fundamentos y entender qué hace cada etapa del procesamiento.
17.19 Ventajas principales
Podemos resumir las grandes ventajas de NLTK así:
- Muy didáctica.
- Rica en recursos clásicos.
- Buena para aprender fundamentos.
- Flexible para experimentación.
- Amplia documentación y tradición educativa.
17.20 Limitaciones principales
También conviene tener presentes sus límites:
- No siempre es la opción más eficiente para producción.
- No es la herramienta principal para Transformers o Deep Learning moderno.
- Puede requerir descargar recursos auxiliares específicos.
- Algunas tareas modernas se resuelven más cómodamente con otras bibliotecas.
17.21 Resumen comparativo con spaCy
| Aspecto | NLTK | spaCy |
|---|---|---|
| Enfoque principal | Didáctico y clásico. | Eficiente y orientado a pipelines. |
| Uso típico | Aprendizaje y exploración. | Procesamiento práctico en aplicaciones. |
| Fortaleza destacada | Fundamentos y corpora. | Rendimiento y componentes productivos. |
17.22 Ejemplo en Python: exploración completa con NLTK
Este ejemplo usa NLTK para tokenizar, quitar stopwords y obtener las palabras más frecuentes de una colección de opiniones. Es más interesante que un ejemplo mínimo porque recorre varias etapas clásicas del pipeline.
import nltk
from nltk.corpus import stopwords
from nltk.probability import FreqDist
nltk.download("punkt")
nltk.download("stopwords")
comentarios = [
"El servicio fue rapido y amable",
"La entrega fue lenta pero el producto llego bien",
"El soporte fue amable y resolvio el problema rapido"
]
tokens = []
stop_es = set(stopwords.words("spanish"))
for texto in comentarios:
for token in nltk.word_tokenize(texto.lower(), language="spanish"):
if token.isalpha() and token not in stop_es:
tokens.append(token)
frecuencias = FreqDist(tokens)
print(frecuencias.most_common(10))Con muy pocas líneas ya podemos inspeccionar qué términos dominan un conjunto de comentarios. Ese tipo de exploración rápida es una de las razones por las que NLTK sigue siendo tan valiosa en contextos educativos.
17.23 Ejemplo en Python: aplicación didáctica de escritorio con NLTK
Este programa construye una aplicación de escritorio con interfaz gráfica usando tkinter. En términos generales, funciona como un pequeño laboratorio interactivo para explorar varias tareas clásicas de NLP con NLTK: descarga de recursos, tokenización, frecuencias léxicas, eliminación de stopwords, stemming, lematización, trabajo con corpora, etiquetado gramatical y una demo simple de clasificación.
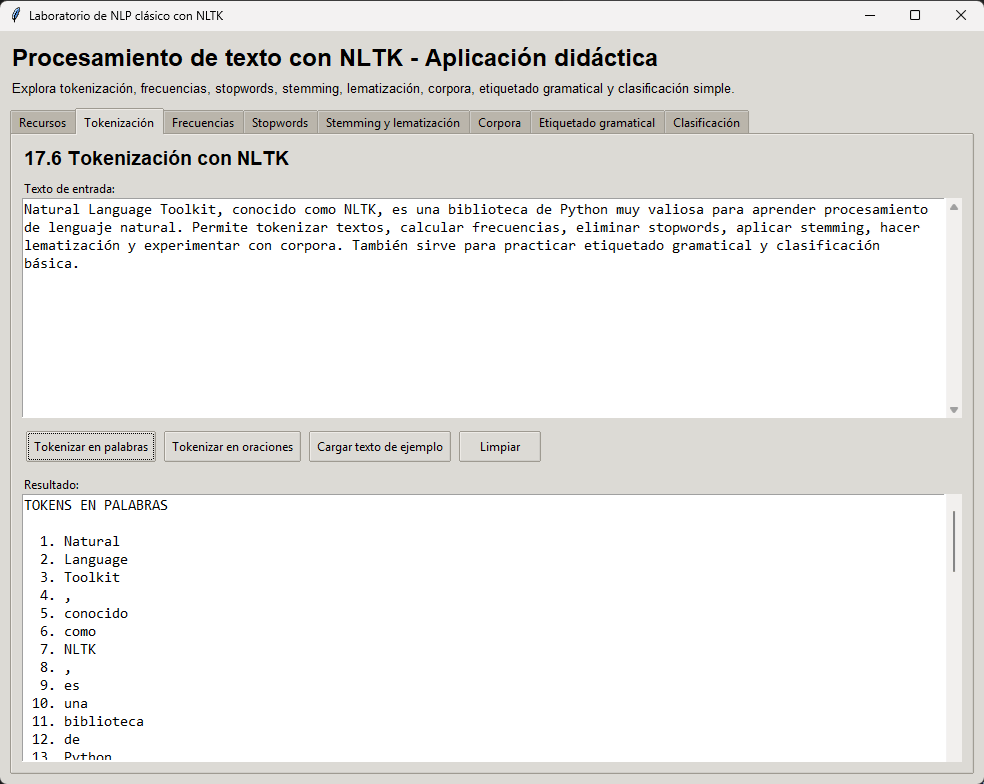
La idea del ejemplo no es solo ejecutar una función aislada, sino mostrar cómo integrar varias capacidades de NLTK dentro de una aplicación completa, donde el usuario puede escribir texto, pulsar botones y ver resultados en pantalla.
import tkinter as tk
from tkinter import ttk, messagebox
from tkinter.scrolledtext import ScrolledText
import threading
import random
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.probability import FreqDist
from nltk.corpus import stopwords, gutenberg, movie_reviews
from nltk.stem import PorterStemmer, SnowballStemmer, WordNetLemmatizer
from nltk import pos_tag, NaiveBayesClassifier, classify
class AplicacionNLTK:
def __init__(self, root):
self.root = root
self.root.title("Laboratorio de NLP clásico con NLTK")
self.root.geometry("1500x930")
self.clasificador = None
self.palabras_mas_frecuentes_clasificador = None
self.entrenando_clasificador = False
self.texto_ejemplo = (
"Natural Language Toolkit, conocido como NLTK, es una biblioteca de Python "
"muy valiosa para aprender procesamiento de lenguaje natural. "
"Permite tokenizar textos, calcular frecuencias, eliminar stopwords, "
"aplicar stemming, hacer lematización y experimentar con corpora. "
"También sirve para practicar etiquetado gramatical y clasificación básica."
)
self.crear_interfaz()
def crear_interfaz(self):
estilo = ttk.Style()
try:
estilo.theme_use("clam")
except:
pass
marco_principal = ttk.Frame(self.root, padding=10)
marco_principal.pack(fill="both", expand=True)
cabecera = ttk.Frame(marco_principal)
cabecera.pack(fill="x", pady=(0, 10))
ttk.Label(
cabecera,
text="Procesamiento de texto con NLTK - Aplicación didáctica",
font=("Arial", 18, "bold")
).pack(anchor="w")
ttk.Label(
cabecera,
text=(
"Explora tokenización, frecuencias, stopwords, stemming, lematización, "
"corpora, etiquetado gramatical y clasificación simple."
),
font=("Arial", 10)
).pack(anchor="w", pady=(4, 0))
self.notebook = ttk.Notebook(marco_principal)
self.notebook.pack(fill="both", expand=True)
self.crear_pestana_recursos()
self.crear_pestana_tokenizacion()
self.crear_pestana_frecuencias()
self.crear_pestana_stopwords()
self.crear_pestana_stemming_lematizacion()
self.crear_pestana_corpora()
self.crear_pestana_etiquetado()
self.crear_pestana_clasificacion()
def insertar_texto(self, widget, texto):
widget.config(state="normal")
widget.delete("1.0", tk.END)
widget.insert(tk.END, texto)
widget.config(state="normal")
def obtener_texto_desde_widget(self, widget):
return widget.get("1.0", tk.END).strip()
def mostrar_error(self, titulo, mensaje):
messagebox.showerror(titulo, mensaje)
def mostrar_info(self, titulo, mensaje):
messagebox.showinfo(titulo, mensaje)
def descargar_recurso_en_hilo(self, nombre_recurso, label_estado=None):
def tarea():
try:
if label_estado:
label_estado.config(text=f"Descargando recurso: {nombre_recurso}...")
nltk.download(nombre_recurso, quiet=False)
if label_estado:
label_estado.config(text=f"Recurso '{nombre_recurso}' descargado correctamente.")
except Exception as e:
if label_estado:
label_estado.config(text=f"Error al descargar '{nombre_recurso}': {e}")
threading.Thread(target=tarea, daemon=True).start()
def descargar_todos_en_hilo(self):
recursos = [
"punkt",
"stopwords",
"wordnet",
"omw-1.4",
"averaged_perceptron_tagger",
"averaged_perceptron_tagger_eng",
"gutenberg",
"movie_reviews"
]
def tarea():
self.label_estado_recursos.config(text="Descargando recursos principales...")
try:
for r in recursos:
try:
nltk.download(r, quiet=True)
except:
pass
self.label_estado_recursos.config(
text="Recursos descargados. Ya puedes probar todas las pestañas."
)
except Exception as e:
self.label_estado_recursos.config(text=f"Error durante la descarga: {e}")
threading.Thread(target=tarea, daemon=True).start()
def extraer_palabras_basicas(self, texto):
try:
tokens = word_tokenize(texto, language="english")
except:
tokens = texto.split()
palabras = []
for t in tokens:
if any(c.isalnum() for c in t):
palabras.append(t)
return palabras
def intentar_pos_tag(self, tokens):
try:
return pos_tag(tokens, lang="eng")
except TypeError:
return pos_tag(tokens)
except LookupError:
nltk.download("averaged_perceptron_tagger")
try:
return pos_tag(tokens, lang="eng")
except:
return pos_tag(tokens)
def crear_pestana_recursos(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Recursos")
izquierda = ttk.Frame(tab)
izquierda.pack(side="left", fill="both", expand=True, padx=(0, 8))
derecha = ttk.Frame(tab)
derecha.pack(side="left", fill="both", expand=True)
ttk.Label(
izquierda,
text="17.4 Instalación y recursos descargables",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
texto_info = (
"NLTK necesita descargar recursos auxiliares para muchas tareas.\n\n"
"Ejemplos:\n"
"- punkt: tokenización\n"
"- stopwords: listas de palabras vacías\n"
"- wordnet y omw-1.4: lematización\n"
"- averaged_perceptron_tagger: etiquetado gramatical\n"
"- gutenberg: corpus de ejemplo\n"
"- movie_reviews: corpus para clasificación\n\n"
"Puedes descargar cada recurso individualmente o todos juntos."
)
self.txt_info_recursos = ScrolledText(izquierda, wrap="word", font=("Consolas", 11), height=20)
self.txt_info_recursos.pack(fill="both", expand=True)
self.txt_info_recursos.insert(tk.END, texto_info)
botones = ttk.Frame(derecha)
botones.pack(fill="x", pady=(0, 10))
ttk.Button(
botones,
text="Descargar TODOS los recursos principales",
command=self.descargar_todos_en_hilo
).pack(fill="x", pady=4)
recursos_individuales = [
"punkt", "stopwords", "wordnet", "omw-1.4",
"averaged_perceptron_tagger", "averaged_perceptron_tagger_eng",
"gutenberg", "movie_reviews"
]
ttk.Label(
derecha,
text="Descarga individual",
font=("Arial", 12, "bold")
).pack(anchor="w", pady=(10, 5))
for recurso in recursos_individuales:
ttk.Button(
derecha,
text=f"Descargar {recurso}",
command=lambda r=recurso: self.descargar_recurso_en_hilo(r, self.label_estado_recursos)
).pack(fill="x", pady=2)
self.label_estado_recursos = ttk.Label(
derecha,
text="Estado: aún no se descargaron recursos.",
foreground="blue"
)
self.label_estado_recursos.pack(anchor="w", pady=(15, 0))
def crear_pestana_tokenizacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Tokenización")
superior = ttk.Frame(tab)
superior.pack(fill="both", expand=True)
ttk.Label(
superior,
text="17.6 Tokenización con NLTK",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(superior, text="Texto de entrada:").pack(anchor="w")
self.txt_tokenizacion_entrada = ScrolledText(superior, wrap="word", height=12, font=("Consolas", 11))
self.txt_tokenizacion_entrada.pack(fill="x", pady=(0, 8))
self.txt_tokenizacion_entrada.insert(tk.END, self.texto_ejemplo)
frame_botones = ttk.Frame(superior)
frame_botones.pack(fill="x", pady=5)
ttk.Button(frame_botones, text="Tokenizar en palabras", command=self.tokenizar_palabras).pack(side="left", padx=4)
ttk.Button(frame_botones, text="Tokenizar en oraciones", command=self.tokenizar_oraciones).pack(side="left", padx=4)
ttk.Button(frame_botones, text="Cargar texto de ejemplo", command=self.cargar_texto_ejemplo_tokenizacion).pack(side="left", padx=4)
ttk.Button(frame_botones, text="Limpiar", command=lambda: self.txt_tokenizacion_salida.delete("1.0", tk.END)).pack(side="left", padx=4)
ttk.Label(superior, text="Resultado:").pack(anchor="w", pady=(8, 0))
self.txt_tokenizacion_salida = ScrolledText(superior, wrap="word", height=18, font=("Consolas", 11))
self.txt_tokenizacion_salida.pack(fill="both", expand=True)
def cargar_texto_ejemplo_tokenizacion(self):
self.txt_tokenizacion_entrada.delete("1.0", tk.END)
self.txt_tokenizacion_entrada.insert(tk.END, self.texto_ejemplo)
def tokenizar_palabras(self):
texto = self.obtener_texto_desde_widget(self.txt_tokenizacion_entrada)
if not texto:
self.mostrar_error("Error", "Ingresa un texto.")
return
try:
tokens = word_tokenize(texto)
salida = "TOKENS EN PALABRAS\n\n"
for i, token in enumerate(tokens, start=1):
salida += f"{i:>3}. {token}\n"
salida += f"\nCantidad total de tokens: {len(tokens)}"
self.insertar_texto(self.txt_tokenizacion_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el recurso 'punkt'. Ve a la pestaña Recursos y descárgalo."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def tokenizar_oraciones(self):
texto = self.obtener_texto_desde_widget(self.txt_tokenizacion_entrada)
if not texto:
self.mostrar_error("Error", "Ingresa un texto.")
return
try:
oraciones = sent_tokenize(texto)
salida = "TOKENS EN ORACIONES\n\n"
for i, oracion in enumerate(oraciones, start=1):
salida += f"Oración {i}:\n{oracion}\n\n"
salida += f"Cantidad total de oraciones: {len(oraciones)}"
self.insertar_texto(self.txt_tokenizacion_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el recurso 'punkt'. Ve a la pestaña Recursos y descárgalo."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def crear_pestana_frecuencias(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Frecuencias")
ttk.Label(
tab,
text="17.7 Frecuencias léxicas",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Texto de entrada:").pack(anchor="w")
self.txt_frecuencias_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_frecuencias_entrada.pack(fill="x", pady=(0, 8))
self.txt_frecuencias_entrada.insert(tk.END, self.texto_ejemplo)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=5)
ttk.Label(controles, text="Top N:").pack(side="left", padx=(0, 5))
self.entry_top_n = ttk.Entry(controles, width=8)
self.entry_top_n.pack(side="left")
self.entry_top_n.insert(0, "15")
self.var_minusculas = tk.BooleanVar(value=True)
ttk.Checkbutton(
controles,
text="Pasar a minúsculas",
variable=self.var_minusculas
).pack(side="left", padx=10)
ttk.Button(controles, text="Calcular frecuencias", command=self.calcular_frecuencias).pack(side="left", padx=5)
ttk.Button(controles, text="Limpiar salida", command=lambda: self.txt_frecuencias_salida.delete("1.0", tk.END)).pack(side="left", padx=5)
ttk.Label(tab, text="Resultado:").pack(anchor="w", pady=(8, 0))
self.txt_frecuencias_salida = ScrolledText(tab, wrap="word", height=18, font=("Consolas", 11))
self.txt_frecuencias_salida.pack(fill="both", expand=True)
def calcular_frecuencias(self):
texto = self.obtener_texto_desde_widget(self.txt_frecuencias_entrada)
if not texto:
self.mostrar_error("Error", "Ingresa un texto.")
return
try:
top_n = int(self.entry_top_n.get())
except:
self.mostrar_error("Error", "Top N debe ser un número entero.")
return
try:
palabras = self.extraer_palabras_basicas(texto)
if self.var_minusculas.get():
palabras = [p.lower() for p in palabras]
freq = FreqDist(palabras)
mas_comunes = freq.most_common(top_n)
salida = "FRECUENCIAS LÉXICAS\n\n"
salida += f"Cantidad total de palabras consideradas: {len(palabras)}\n"
salida += f"Cantidad de palabras únicas: {len(freq)}\n\n"
salida += "TOP DE TÉRMINOS MÁS FRECUENTES\n"
salida += "-" * 40 + "\n"
for i, (palabra, cantidad) in enumerate(mas_comunes, start=1):
salida += f"{i:>3}. {palabra:<20} -> {cantidad}\n"
self.insertar_texto(self.txt_frecuencias_salida, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
def crear_pestana_stopwords(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Stopwords")
ttk.Label(
tab,
text="17.8 Stopwords con NLTK",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Texto de entrada:").pack(anchor="w")
self.txt_stopwords_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_stopwords_entrada.pack(fill="x", pady=(0, 8))
self.txt_stopwords_entrada.insert(
tk.END,
"Este es un ejemplo de texto en español para mostrar cómo se eliminan las palabras "
"muy frecuentes que suelen aportar poco contenido semántico en determinados análisis."
)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=5)
ttk.Label(controles, text="Idioma stopwords:").pack(side="left", padx=(0, 5))
self.combo_idioma_stopwords = ttk.Combobox(
controles,
values=["spanish", "english", "portuguese", "french", "german", "italian"],
state="readonly",
width=15
)
self.combo_idioma_stopwords.pack(side="left")
self.combo_idioma_stopwords.set("spanish")
ttk.Button(controles, text="Aplicar stopwords", command=self.aplicar_stopwords).pack(side="left", padx=8)
ttk.Button(controles, text="Mostrar lista stopwords", command=self.mostrar_lista_stopwords).pack(side="left", padx=8)
ttk.Label(tab, text="Resultado:").pack(anchor="w", pady=(8, 0))
self.txt_stopwords_salida = ScrolledText(tab, wrap="word", height=18, font=("Consolas", 11))
self.txt_stopwords_salida.pack(fill="both", expand=True)
def aplicar_stopwords(self):
texto = self.obtener_texto_desde_widget(self.txt_stopwords_entrada)
idioma = self.combo_idioma_stopwords.get()
if not texto:
self.mostrar_error("Error", "Ingresa un texto.")
return
try:
lista_stopwords = set(stopwords.words(idioma))
tokens = self.extraer_palabras_basicas(texto.lower())
tokens_filtrados = [t for t in tokens if t not in lista_stopwords]
salida = "ELIMINACIÓN DE STOPWORDS\n\n"
salida += f"Idioma seleccionado: {idioma}\n\n"
salida += f"Tokens originales ({len(tokens)}):\n{tokens}\n\n"
salida += f"Tokens filtrados ({len(tokens_filtrados)}):\n{tokens_filtrados}\n\n"
salida += "Texto reconstruido aproximado:\n"
salida += " ".join(tokens_filtrados)
self.insertar_texto(self.txt_stopwords_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el recurso 'stopwords'. Ve a la pestaña Recursos y descárgalo."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def mostrar_lista_stopwords(self):
idioma = self.combo_idioma_stopwords.get()
try:
lista = stopwords.words(idioma)
salida = f"STOPWORDS DEL IDIOMA: {idioma}\n\n"
salida += ", ".join(lista)
self.insertar_texto(self.txt_stopwords_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el recurso 'stopwords'. Ve a la pestaña Recursos y descárgalo."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def crear_pestana_stemming_lematizacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Stemming y lematización")
ttk.Label(
tab,
text="17.9 Stemming y 17.10 Lematización",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Palabras de entrada (separadas por espacios):").pack(anchor="w")
self.txt_stem_lem_entrada = ScrolledText(tab, wrap="word", height=8, font=("Consolas", 11))
self.txt_stem_lem_entrada.pack(fill="x", pady=(0, 8))
self.txt_stem_lem_entrada.insert(
tk.END,
"running runs runner studies studying studied cars wolves better children mice"
)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=5)
ttk.Button(controles, text="Aplicar Porter Stemmer", command=self.aplicar_porter).pack(side="left", padx=4)
ttk.Button(controles, text="Aplicar Snowball Stemmer (español)", command=self.aplicar_snowball_es).pack(side="left", padx=4)
ttk.Button(controles, text="Aplicar WordNet Lemmatizer", command=self.aplicar_lematizador).pack(side="left", padx=4)
ttk.Label(tab, text="Resultado:").pack(anchor="w", pady=(8, 0))
self.txt_stem_lem_salida = ScrolledText(tab, wrap="word", height=22, font=("Consolas", 11))
self.txt_stem_lem_salida.pack(fill="both", expand=True)
def obtener_lista_palabras_stem_lem(self):
texto = self.obtener_texto_desde_widget(self.txt_stem_lem_entrada)
if not texto:
return []
return texto.split()
def aplicar_porter(self):
palabras = self.obtener_lista_palabras_stem_lem()
if not palabras:
self.mostrar_error("Error", "Ingresa palabras.")
return
stemmer = PorterStemmer()
salida = "PORTER STEMMER\n\n"
for palabra in palabras:
salida += f"{palabra:<20} -> {stemmer.stem(palabra)}\n"
self.insertar_texto(self.txt_stem_lem_salida, salida)
def aplicar_snowball_es(self):
palabras = self.obtener_lista_palabras_stem_lem()
if not palabras:
self.mostrar_error("Error", "Ingresa palabras.")
return
try:
stemmer = SnowballStemmer("spanish")
salida = "SNOWBALL STEMMER (ESPAÑOL)\n\n"
for palabra in palabras:
salida += f"{palabra:<20} -> {stemmer.stem(palabra)}\n"
self.insertar_texto(self.txt_stem_lem_salida, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
def aplicar_lematizador(self):
palabras = self.obtener_lista_palabras_stem_lem()
if not palabras:
self.mostrar_error("Error", "Ingresa palabras.")
return
try:
lematizador = WordNetLemmatizer()
salida = "WORDNET LEMMATIZER\n\n"
salida += "Lematización como sustantivo (por defecto):\n\n"
for palabra in palabras:
salida += f"{palabra:<20} -> {lematizador.lemmatize(palabra)}\n"
salida += "\nLematización como verbo:\n\n"
for palabra in palabras:
salida += f"{palabra:<20} -> {lematizador.lemmatize(palabra, pos='v')}\n"
self.insertar_texto(self.txt_stem_lem_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Faltan recursos de WordNet. Descarga 'wordnet' y 'omw-1.4' en la pestaña Recursos."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def crear_pestana_corpora(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Corpora")
ttk.Label(
tab,
text="17.11 Trabajo con corpora",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Listar archivos de Gutenberg", command=self.listar_corpus_gutenberg).pack(side="left", padx=4)
ttk.Button(controles, text="Mostrar fragmento aleatorio", command=self.mostrar_fragmento_gutenberg).pack(side="left", padx=4)
ttk.Button(controles, text="Estadísticas del corpus", command=self.estadisticas_gutenberg).pack(side="left", padx=4)
self.txt_corpora_salida = ScrolledText(tab, wrap="word", height=30, font=("Consolas", 11))
self.txt_corpora_salida.pack(fill="both", expand=True)
def listar_corpus_gutenberg(self):
try:
archivos = gutenberg.fileids()
salida = "ARCHIVOS DISPONIBLES EN GUTENBERG\n\n"
for i, archivo in enumerate(archivos, start=1):
salida += f"{i:>2}. {archivo}\n"
self.insertar_texto(self.txt_corpora_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el corpus 'gutenberg'. Descárgalo en la pestaña Recursos."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def mostrar_fragmento_gutenberg(self):
try:
archivos = gutenberg.fileids()
archivo = random.choice(archivos)
palabras = gutenberg.words(archivo)
inicio = random.randint(0, max(0, len(palabras) - 200))
fragmento = palabras[inicio:inicio + 200]
salida = f"FRAGMENTO ALEATORIO DE GUTENBERG\n\nArchivo: {archivo}\n\n"
salida += " ".join(fragmento)
self.insertar_texto(self.txt_corpora_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el corpus 'gutenberg'. Descárgalo en la pestaña Recursos."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def estadisticas_gutenberg(self):
try:
archivos = gutenberg.fileids()
salida = "ESTADÍSTICAS BÁSICAS DE GUTENBERG\n\n"
salida += f"{'Archivo':<30} {'Palabras':>10} {'Oraciones':>12} {'Vocabulario':>12}\n"
salida += "-" * 70 + "\n"
for archivo in archivos[:8]:
num_palabras = len(gutenberg.words(archivo))
num_oraciones = len(gutenberg.sents(archivo))
vocabulario = len(set(w.lower() for w in gutenberg.words(archivo) if w.isalpha()))
salida += f"{archivo:<30} {num_palabras:>10} {num_oraciones:>12} {vocabulario:>12}\n"
salida += "\n(Se muestran los primeros archivos para que la salida sea legible.)"
self.insertar_texto(self.txt_corpora_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Falta el corpus 'gutenberg'. Descárgalo en la pestaña Recursos."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def crear_pestana_etiquetado(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Etiquetado gramatical")
ttk.Label(
tab,
text="17.12 Etiquetado y análisis lingüístico básico",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(
tab,
text=(
"Nota: el etiquetado POS clásico de NLTK funciona mejor sobre texto en inglés. "
"Para una demo clara, conviene probar con una oración inglesa."
),
foreground="darkgreen"
).pack(anchor="w", pady=(0, 8))
self.txt_etiquetado_entrada = ScrolledText(tab, wrap="word", height=8, font=("Consolas", 11))
self.txt_etiquetado_entrada.pack(fill="x", pady=(0, 8))
self.txt_etiquetado_entrada.insert(
tk.END,
"The quick brown fox jumps over the lazy dog and studies natural language processing."
)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=5)
ttk.Button(controles, text="Etiquetar texto", command=self.etiquetar_texto).pack(side="left", padx=4)
ttk.Button(controles, text="Cargar ejemplo", command=self.cargar_ejemplo_etiquetado).pack(side="left", padx=4)
self.txt_etiquetado_salida = ScrolledText(tab, wrap="word", height=24, font=("Consolas", 11))
self.txt_etiquetado_salida.pack(fill="both", expand=True)
def cargar_ejemplo_etiquetado(self):
self.txt_etiquetado_entrada.delete("1.0", tk.END)
self.txt_etiquetado_entrada.insert(
tk.END,
"The quick brown fox jumps over the lazy dog and studies natural language processing."
)
def etiquetar_texto(self):
texto = self.obtener_texto_desde_widget(self.txt_etiquetado_entrada)
if not texto:
self.mostrar_error("Error", "Ingresa un texto.")
return
try:
tokens = word_tokenize(texto)
etiquetas = self.intentar_pos_tag(tokens)
salida = "ETIQUETADO GRAMATICAL (POS TAGGING)\n\n"
salida += f"{'TOKEN':<20} {'ETIQUETA':<15}\n"
salida += "-" * 40 + "\n"
for token, etiqueta in etiquetas:
salida += f"{token:<20} {etiqueta:<15}\n"
salida += (
"\nObservación:\n"
"Estas etiquetas corresponden al esquema clásico de POS tagging en inglés."
)
self.insertar_texto(self.txt_etiquetado_salida, salida)
except LookupError:
self.mostrar_error(
"Recurso faltante",
"Faltan recursos de tokenización o tagging. Descarga 'punkt' y 'averaged_perceptron_tagger'."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def crear_pestana_clasificacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Clasificación")
ttk.Label(
tab,
text="17.13 Clasificación y experimentación simple",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(
tab,
text=(
"Demo clásica con Naive Bayes sobre movie_reviews. "
"Este corpus está en inglés, así que la clasificación de prueba también conviene hacerla en inglés."
),
foreground="darkblue"
).pack(anchor="w", pady=(0, 8))
frame_sup = ttk.Frame(tab)
frame_sup.pack(fill="x", pady=(0, 8))
ttk.Button(frame_sup, text="Entrenar clasificador demo", command=self.entrenar_clasificador_demo).pack(side="left", padx=4)
self.label_estado_clasificador = ttk.Label(
frame_sup,
text="Estado: clasificador no entrenado.",
foreground="purple"
)
self.label_estado_clasificador.pack(side="left", padx=10)
ttk.Label(tab, text="Texto a clasificar:").pack(anchor="w")
self.txt_clasificacion_entrada = ScrolledText(tab, wrap="word", height=6, font=("Consolas", 11))
self.txt_clasificacion_entrada.pack(fill="x", pady=(0, 8))
self.txt_clasificacion_entrada.insert(
tk.END,
"This movie was wonderful, emotional, intelligent and beautifully directed."
)
frame_bot = ttk.Frame(tab)
frame_bot.pack(fill="x", pady=5)
ttk.Button(frame_bot, text="Clasificar texto", command=self.clasificar_texto_demo).pack(side="left", padx=4)
ttk.Button(frame_bot, text="Ejemplo positivo", command=self.cargar_ejemplo_positivo).pack(side="left", padx=4)
ttk.Button(frame_bot, text="Ejemplo negativo", command=self.cargar_ejemplo_negativo).pack(side="left", padx=4)
self.txt_clasificacion_salida = ScrolledText(tab, wrap="word", height=20, font=("Consolas", 11))
self.txt_clasificacion_salida.pack(fill="both", expand=True)
def cargar_ejemplo_positivo(self):
self.txt_clasificacion_entrada.delete("1.0", tk.END)
self.txt_clasificacion_entrada.insert(
tk.END,
"This movie was wonderful, emotional, intelligent and beautifully directed."
)
def cargar_ejemplo_negativo(self):
self.txt_clasificacion_entrada.delete("1.0", tk.END)
self.txt_clasificacion_entrada.insert(
tk.END,
"The film was boring, predictable, slow and full of terrible performances."
)
def documento_a_features(self, palabras_documento):
conjunto_palabras = set(palabras_documento)
return {
palabra: (palabra in conjunto_palabras)
for palabra in self.palabras_mas_frecuentes_clasificador
}
def entrenar_clasificador_demo(self):
if self.entrenando_clasificador:
return
def tarea():
self.entrenando_clasificador = True
self.label_estado_clasificador.config(text="Entrenando clasificador...", foreground="orange")
try:
documentos = [
(list(movie_reviews.words(fileid)), categoria)
for categoria in movie_reviews.categories()
for fileid in movie_reviews.fileids(categoria)
]
random.shuffle(documentos)
todas_las_palabras = nltk.FreqDist(
w.lower()
for w in movie_reviews.words()
if w.isalpha()
)
self.palabras_mas_frecuentes_clasificador = list(todas_las_palabras)[:2000]
featuresets = [
(self.documento_a_features([w.lower() for w in palabras]), categoria)
for palabras, categoria in documentos
]
entrenamiento = featuresets[:1600]
prueba = featuresets[1600:1900]
self.clasificador = NaiveBayesClassifier.train(entrenamiento)
exactitud = classify.accuracy(self.clasificador, prueba) * 100
salida = "CLASIFICADOR ENTRENADO\n\n"
salida += "Modelo: Naive Bayes clásico\n"
salida += "Corpus: movie_reviews\n"
salida += f"Cantidad de features léxicas: {len(self.palabras_mas_frecuentes_clasificador)}\n"
salida += f"Exactitud aproximada sobre conjunto de prueba: {exactitud:.2f}%\n\n"
salida += "Características más informativas:\n"
try:
import io
import contextlib
buffer = io.StringIO()
with contextlib.redirect_stdout(buffer):
self.clasificador.show_most_informative_features(15)
salida += buffer.getvalue()
except:
salida += "(No se pudieron mostrar en formato capturado, pero el modelo fue entrenado.)"
self.insertar_texto(self.txt_clasificacion_salida, salida)
self.label_estado_clasificador.config(
text=f"Clasificador listo. Exactitud aprox.: {exactitud:.2f}%",
foreground="green"
)
except LookupError:
self.label_estado_clasificador.config(
text="Falta el corpus movie_reviews.",
foreground="red"
)
self.mostrar_error(
"Recurso faltante",
"Falta el corpus 'movie_reviews'. Descárgalo en la pestaña Recursos."
)
except Exception as e:
self.label_estado_clasificador.config(text="Error al entrenar.", foreground="red")
self.mostrar_error("Error", str(e))
finally:
self.entrenando_clasificador = False
threading.Thread(target=tarea, daemon=True).start()
def clasificar_texto_demo(self):
if self.clasificador is None or self.palabras_mas_frecuentes_clasificador is None:
self.mostrar_error("Error", "Primero debes entrenar el clasificador demo.")
return
texto = self.obtener_texto_desde_widget(self.txt_clasificacion_entrada)
if not texto:
self.mostrar_error("Error", "Ingresa un texto.")
return
try:
tokens = [w.lower() for w in self.extraer_palabras_basicas(texto)]
features = self.documento_a_features(tokens)
categoria = self.clasificador.classify(features)
distribucion = self.clasificador.prob_classify(features)
prob_pos = distribucion.prob("pos")
prob_neg = distribucion.prob("neg")
salida = "CLASIFICACIÓN DEL TEXTO\n\n"
salida += f"Texto analizado:\n{texto}\n\n"
salida += f"Categoría predicha: {categoria}\n"
salida += f"Probabilidad positiva: {prob_pos:.4f}\n"
salida += f"Probabilidad negativa: {prob_neg:.4f}\n\n"
salida += (
"Importante:\n"
"Esta es una demo educativa de NLP clásico, no un sistema moderno de análisis de sentimiento."
)
self.insertar_texto(self.txt_clasificacion_salida, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
if __name__ == "__main__":
root = tk.Tk()
app = AplicacionNLTK(root)
root.mainloop()La estructura del programa puede entenderse en varios bloques. Primero se importan bibliotecas de interfaz gráfica, hilos y utilidades de NLTK. Luego se define la clase AplicacionNLTK, que organiza toda la aplicación. Dentro de esa clase se crean las pestañas, los campos de texto, los botones y las funciones que reaccionan a cada acción del usuario.
Las pestañas cumplen objetivos concretos. La pestaña de recursos descarga los datos auxiliares que NLTK necesita. La pestaña de tokenización separa texto en palabras u oraciones. La de frecuencias calcula términos más repetidos. La de stopwords elimina palabras vacías. La de stemming y lematización transforma palabras a formas más básicas. La de corpora explora colecciones de textos ya incluidas en NLTK. La de etiquetado aplica POS tagging. Finalmente, la de clasificación entrena un Naive Bayes sencillo sobre movie_reviews.
También es importante notar que varias operaciones se ejecutan en hilos con threading.Thread(..., daemon=True). El objetivo es que la interfaz no se congele mientras se descargan recursos o se entrena el clasificador. Esa decisión mejora mucho la usabilidad de una aplicación de escritorio.
Este ejemplo es más grande que los anteriores, pero justamente por eso resulta útil: muestra cómo NLTK puede pasar de pequeños scripts sueltos a una herramienta interactiva que reúne varias técnicas clásicas en un solo entorno.
17.24 Qué debes recordar de este tema
- NLTK es una biblioteca clásica y muy útil para aprender NLP en Python.
- Ofrece herramientas para tokenización, stopwords, stemming, lematización, corpora y análisis básico.
- Su mayor fortaleza está en el aprendizaje y la experimentación conceptual.
- No siempre es la opción más adecuada para pipelines industriales grandes o modelos modernos.
- Funciona muy bien como puente entre teoría y práctica.
17.25 Conclusión
Trabajar con NLTK es una excelente manera de empezar a aplicar de forma concreta muchos de los conceptos fundamentales del NLP. Su valor no está solo en las funciones que ofrece, sino en que ayuda a ver con claridad qué está ocurriendo en cada etapa del procesamiento de texto.
Por eso sigue siendo una herramienta formativa muy importante, incluso en un ecosistema donde existen bibliotecas más modernas o más optimizadas para producción.
En el próximo tema estudiaremos el procesamiento de texto con spaCy, para contrastar este enfoque con una biblioteca más orientada a eficiencia y pipelines productivos.