18. Procesamiento de texto con spaCy
18.1 Introducción
En el tema anterior vimos cómo NLTK resulta muy útil para aprender fundamentos de NLP y experimentar con técnicas clásicas. Ahora vamos a estudiar otra biblioteca muy importante del ecosistema Python: spaCy.
Mientras que NLTK se destaca por su valor didáctico, spaCy suele destacarse por su eficiencia, su diseño orientado a pipelines y su utilidad práctica en aplicaciones reales. Por eso ocupa un lugar muy importante cuando el objetivo ya no es solo aprender conceptos, sino también procesar texto de forma robusta y estructurada.
En este tema construiremos una visión conceptual de cómo se trabaja con spaCy y por qué se convirtió en una herramienta tan popular en NLP aplicado.
18.2 ¿Qué es spaCy?
spaCy es una biblioteca de NLP para Python diseñada con foco en rendimiento, facilidad de integración y uso práctico. Su objetivo no es solo ofrecer funciones aisladas, sino permitir construir pipelines lingüísticos eficientes sobre texto real.
Esto la vuelve especialmente atractiva para proyectos donde importa procesar muchos documentos, extraer información estructurada o integrar NLP en sistemas más grandes.
18.3 La idea de pipeline
Uno de los conceptos más importantes en spaCy es el de pipeline. Un pipeline es una secuencia de componentes que se aplican sobre un texto para enriquecerlo progresivamente.
Por ejemplo, un pipeline puede incluir:
- Tokenización.
- Lematización.
- Etiquetado gramatical.
- Reconocimiento de entidades.
- Análisis de dependencias.
La gran ventaja de esta idea es que el texto entra como una cadena simple y sale como un objeto enriquecido con múltiples niveles de análisis.
18.4 El objeto documento
En spaCy, el procesamiento suele organizarse alrededor de un objeto central que representa el documento ya analizado. Ese objeto contiene el texto original, los tokens y mucha información derivada generada por el pipeline.
Esto permite trabajar sobre una estructura unificada donde cada token puede tener atributos como:
- Texto original.
- Lema.
- Categoría gramatical.
- Relación sintáctica.
- Pertenencia a una entidad nombrada.
Desde el punto de vista práctico, esto hace muy cómodo recorrer y explotar análisis lingüísticos complejos.
18.5 Tokenización con spaCy
spaCy ofrece un sistema de tokenización robusto y muy importante dentro de su pipeline. A diferencia de una segmentación trivial por espacios, su tokenizador considera múltiples reglas para signos, abreviaturas, contracciones y otros casos que aparecen en texto real.
Esto es especialmente valioso porque muchas tareas posteriores dependen directamente de que los tokens estén bien segmentados.
18.6 Lematización y análisis gramatical
Otra gran fortaleza de spaCy es que integra análisis lingüístico más estructurado. No se limita solo a dividir texto, sino que puede asociar a cada token información como su lema y su categoría gramatical.
Esto resulta útil en tareas donde importa distinguir no solo la palabra superficial, sino también su función dentro de la oración.
18.7 Etiquetado gramatical
El etiquetado gramatical consiste en asignar a cada token una categoría como sustantivo, verbo, adjetivo o pronombre. spaCy permite trabajar con este tipo de información de manera relativamente accesible y eficiente.
Desde el punto de vista práctico, esto ayuda a construir reglas, filtrar tokens y enriquecer análisis de forma mucho más lingüística que con un simple procesamiento superficial.
18.8 Reconocimiento de entidades nombradas
Una de las tareas más conocidas y valiosas en spaCy es el reconocimiento de entidades nombradas. Esto consiste en detectar menciones de personas, organizaciones, lugares, fechas, cantidades u otras categorías relevantes dentro del texto.
Por ejemplo, en una oración pueden identificarse:
- Nombres propios.
- Ciudades o países.
- Empresas.
- Fechas.
- Montos monetarios.
Esta capacidad hace que spaCy sea muy útil en extracción de información y procesamiento documental.
18.9 Análisis de dependencias
spaCy también puede trabajar con relaciones sintácticas entre palabras, es decir, con análisis de dependencias. Esto permite modelar cómo se conectan los componentes de una oración y qué función estructural cumple cada token respecto de otros.
Este tipo de información es valiosa cuando no alcanza con saber qué palabras aparecen y necesitamos entender parte de la estructura gramatical de la oración.
18.10 ¿Por qué spaCy se considera eficiente?
spaCy se diseñó con una fuerte orientación al rendimiento. Esto significa que puede procesar texto de manera bastante rápida y estructurada, algo muy importante cuando se trabaja con grandes volúmenes de documentos.
Esa eficiencia lo vuelve especialmente atractivo en escenarios productivos, donde el análisis lingüístico debe integrarse a sistemas reales con restricciones de tiempo y recursos.
18.11 Modelos lingüísticos por idioma
spaCy suele trabajar apoyándose en modelos lingüísticos específicos para cada idioma. Estos modelos contienen recursos y parámetros que permiten realizar tokenización, lematización, etiquetado y otras tareas con cierta calidad para una lengua concreta.
Esto implica que, además de instalar la biblioteca, normalmente se trabaja también con modelos de idioma adecuados al caso de uso.
18.12 ¿Qué tipo de tareas encajan bien con spaCy?
spaCy encaja especialmente bien en tareas como:
- Procesamiento estructurado de documentos.
- Extracción de entidades.
- Pipelines de análisis lingüístico.
- Preprocesamiento eficiente para sistemas mayores.
- Aplicaciones donde importan velocidad y organización del pipeline.
Por eso es muy común en sistemas empresariales, análisis documental y prototipos aplicados.
18.13 ¿Qué no conviene esperar de spaCy?
Aunque es muy poderosa, spaCy no reemplaza por completo a todas las demás herramientas del ecosistema. No es la biblioteca central para entrenar desde cero modelos profundos complejos ni para cubrir por sí sola todo el universo de Transformers modernos.
Su fortaleza principal está en el procesamiento lingüístico estructurado y eficiente, no en ser una solución universal a cualquier problema de NLP.
18.14 Diferencia práctica con NLTK
Comparada con NLTK, spaCy suele sentirse más orientada a pipelines listos para uso práctico. Mientras NLTK invita mucho a explorar conceptos por módulos, spaCy tiende a ofrecer una experiencia más integrada alrededor del documento y del pipeline.
Podemos resumir intuitivamente así:
- NLTK: excelente para aprender piezas sueltas y fundamentos clásicos.
- spaCy: excelente para procesar texto de manera estructurada, rápida y más cercana a producción.
18.15 Ventaja del diseño orientado a objetos
Otra fortaleza de spaCy es que organiza la información en objetos ricos, como documentos, tokens y spans. Esto facilita trabajar de forma cómoda y legible sobre estructuras lingüísticas sin tener que reconstruir manualmente la relación entre partes del texto.
Desde un punto de vista de ingeniería, esto mejora mucho la claridad del código y la mantenibilidad de los pipelines.
18.16 spaCy y extracción de información
Una de las áreas donde spaCy resulta particularmente fuerte es la extracción de información. Si necesitamos detectar entidades, recorrer frases, localizar relaciones sintácticas o filtrar patrones lingüísticos, spaCy ofrece un entorno muy adecuado para hacerlo.
Esto lo convierte en una herramienta especialmente valiosa en aplicaciones documentales, legales, médicas, financieras o de atención al cliente.
18.17 spaCy como capa intermedia en un sistema
En muchos proyectos reales, spaCy no es la única pieza del sistema, sino una capa intermedia de procesamiento. Por ejemplo:
- Un texto entra al sistema.
- spaCy realiza tokenización, entidades y análisis lingüístico.
- Ese resultado se usa luego para reglas, extracción estructurada o modelos posteriores.
De esta forma, spaCy funciona como una infraestructura lingüística muy útil dentro de pipelines mayores.
18.18 Relación con modelos modernos
Aunque spaCy no sea la biblioteca central para entrenar Transformers desde cero, sí puede convivir muy bien con enfoques modernos. En muchos sistemas se usa spaCy para ciertas etapas lingüísticas y otras herramientas para modelos neuronales más pesados o tareas específicas.
Esto refuerza una idea importante del curso: en NLP real, las bibliotecas suelen complementarse.
18.19 Flujo conceptual típico con spaCy
Un flujo conceptual muy típico podría verse así:
- Cargar un modelo lingüístico del idioma.
- Procesar el texto a través del pipeline.
- Obtener un objeto documento enriquecido.
- Recorrer tokens, entidades o dependencias.
- Usar esa información para análisis, extracción o integración con otras capas del sistema.
Esto resume bien la filosofía de trabajo que spaCy promueve.
18.20 Ventajas principales
Podemos resumir las grandes ventajas de spaCy así:
- Buen rendimiento.
- Pipeline bien estructurado.
- Muy útil para entidades y análisis lingüístico.
- Buena orientación a aplicaciones reales.
- Diseño cómodo para trabajar con documentos y tokens.
18.21 Limitaciones principales
También conviene recordar sus límites:
- No reemplaza a bibliotecas de Deep Learning general.
- No cubre por sí sola todo el ecosistema moderno de modelos grandes.
- Depende de modelos lingüísticos adecuados al idioma.
- En algunos contextos didácticos, NLTK puede resultar más transparente para aprender fundamentos básicos.
18.22 Resumen comparativo con NLTK
| Aspecto | NLTK | spaCy |
|---|---|---|
| Foco principal | Didáctica y técnicas clásicas. | Pipelines eficientes y estructurados. |
| Uso típico | Aprendizaje, exploración y corpora. | Procesamiento práctico y extracción de información. |
| Fortaleza destacada | Claridad conceptual. | Rendimiento y diseño productivo. |
18.23 Ejemplo en Python: entidades y dependencias con spaCy
El siguiente ejemplo muestra dos capacidades muy potentes de spaCy en un solo script: reconocimiento de entidades y análisis de dependencias. Es un buen ejemplo porque permite ver que spaCy no solo tokeniza, sino que construye una representación lingüística rica.
import spacy
nlp = spacy.load("es_core_news_sm")
texto = "Lionel Messi anuncio un proyecto educativo en Rosario junto a una empresa de tecnologia."
doc = nlp(texto)
print("Entidades:")
for ent in doc.ents:
print(ent.text, ent.label_)
print("\nDependencias:")
for token in doc:
print(token.text, token.dep_, "->", token.head.text)En un pipeline real, esta información puede usarse para extracción de hechos, búsqueda semántica, clasificación enriquecida o análisis de documentos. Ese es justamente el tipo de trabajo donde spaCy suele destacar.
18.24 Ejemplo en Python: aplicación didáctica de escritorio con spaCy
El objetivo general de esta aplicación es ofrecer un pequeño laboratorio visual para experimentar con spaCy desde una interfaz gráfica. En lugar de ejecutar scripts aislados en consola, el usuario puede cargar modelos, procesar textos, recorrer distintas pestañas y observar de manera interactiva cómo spaCy tokeniza, lematiza, etiqueta, detecta entidades, analiza dependencias y procesa lotes de documentos.
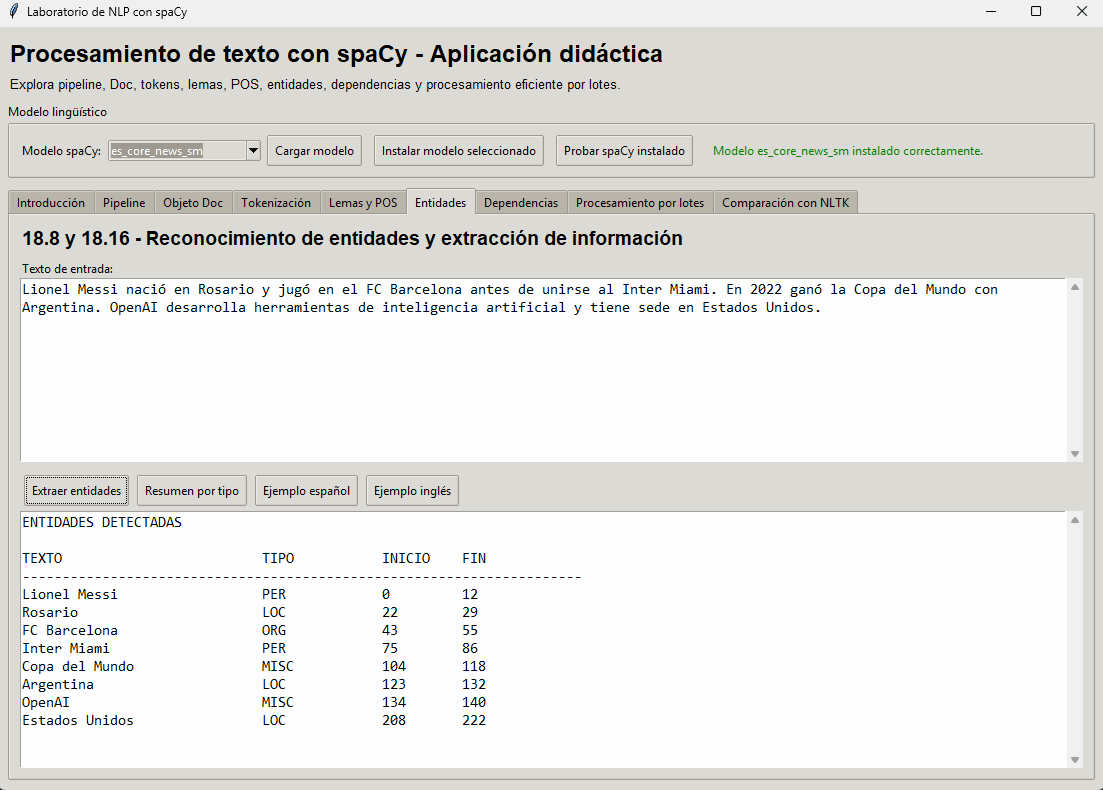
Este tipo de ejemplo resulta valioso porque muestra a spaCy en un contexto más cercano a una aplicación real. No se limita a una sola función, sino que integra varias capacidades del pipeline lingüístico dentro de un entorno único y organizado.
import tkinter as tk
from tkinter import ttk, messagebox
from tkinter.scrolledtext import ScrolledText
import threading
import subprocess
import sys
import time
try:
import spacy
SPACY_INSTALADO = True
except Exception:
SPACY_INSTALADO = False
spacy = None
class AplicacionSpaCy:
def __init__(self, root):
self.root = root
self.root.title("Laboratorio de NLP con spaCy")
self.root.geometry("1600x950")
self.nlp = None
self.modelo_actual = None
self.procesando = False
self.texto_es = (
"Lionel Messi nacio en Rosario y jugo en el FC Barcelona antes de unirse al Inter Miami. "
"En 2022 gano la Copa del Mundo con Argentina. "
"OpenAI desarrolla herramientas de inteligencia artificial y tiene sede en Estados Unidos."
)
self.texto_en = (
"Apple released a new product in California on Monday. "
"John Smith visited New York in 2024 and spent 500 dollars. "
"OpenAI builds artificial intelligence systems for many industries."
)
self.crear_interfaz()
def crear_interfaz(self):
estilo = ttk.Style()
try:
estilo.theme_use("clam")
except:
pass
contenedor = ttk.Frame(self.root, padding=10)
contenedor.pack(fill="both", expand=True)
cabecera = ttk.Frame(contenedor)
cabecera.pack(fill="x", pady=(0, 10))
ttk.Label(
cabecera,
text="Procesamiento de texto con spaCy - Aplicación didáctica",
font=("Arial", 18, "bold")
).pack(anchor="w")
ttk.Label(
cabecera,
text=(
"Explora pipeline, Doc, tokens, lemas, POS, entidades, dependencias "
"y procesamiento eficiente por lotes."
),
font=("Arial", 10)
).pack(anchor="w", pady=(4, 0))
marco_superior = ttk.LabelFrame(contenedor, text="Modelo lingüístico", padding=10)
marco_superior.pack(fill="x", pady=(0, 10))
ttk.Label(marco_superior, text="Modelo spaCy:").pack(side="left", padx=(0, 5))
self.combo_modelos = ttk.Combobox(
marco_superior,
values=[
"es_core_news_sm",
"en_core_web_sm",
"es_core_news_md",
"en_core_web_md"
],
state="readonly",
width=22
)
self.combo_modelos.pack(side="left")
self.combo_modelos.set("es_core_news_sm")
ttk.Button(
marco_superior,
text="Cargar modelo",
command=self.cargar_modelo_en_hilo
).pack(side="left", padx=6)
ttk.Button(
marco_superior,
text="Instalar modelo seleccionado",
command=self.instalar_modelo_en_hilo
).pack(side="left", padx=6)
ttk.Button(
marco_superior,
text="Probar spaCy instalado",
command=self.verificar_spacy
).pack(side="left", padx=6)
self.label_estado_modelo = ttk.Label(
marco_superior,
text="Estado: spaCy no cargado.",
foreground="blue"
)
self.label_estado_modelo.pack(side="left", padx=12)
self.notebook = ttk.Notebook(contenedor)
self.notebook.pack(fill="both", expand=True)
self.crear_pestana_introduccion()
self.crear_pestana_pipeline()
self.crear_pestana_documento()
self.crear_pestana_tokenizacion()
self.crear_pestana_lemas_pos()
self.crear_pestana_entidades()
self.crear_pestana_dependencias()
self.crear_pestana_procesamiento_lotes()
self.crear_pestana_comparacion()
def insertar_texto(self, widget, texto):
widget.config(state="normal")
widget.delete("1.0", tk.END)
widget.insert(tk.END, texto)
widget.config(state="normal")
def obtener_texto(self, widget):
return widget.get("1.0", tk.END).strip()
def mostrar_error(self, titulo, mensaje):
messagebox.showerror(titulo, mensaje)
def mostrar_info(self, titulo, mensaje):
messagebox.showinfo(titulo, mensaje)
def obtener_modelo_seleccionado(self):
return self.combo_modelos.get().strip()
def verificar_spacy(self):
if SPACY_INSTALADO:
self.mostrar_info("spaCy", "spaCy está instalado correctamente.")
else:
self.mostrar_error(
"spaCy no instalado",
"No se pudo importar spaCy.\n\nInstálalo con:\n\npip install spacy"
)
def asegurar_modelo_cargado(self):
if not SPACY_INSTALADO:
self.mostrar_error(
"spaCy no instalado",
"Debes instalar spaCy primero:\n\npip install spacy"
)
return False
if self.nlp is None:
self.mostrar_error(
"Modelo no cargado",
"Primero debes cargar un modelo lingüístico."
)
return False
return True
def instalar_modelo_en_hilo(self):
if not SPACY_INSTALADO:
self.mostrar_error(
"spaCy no instalado",
"Primero instala spaCy con:\n\npip install spacy"
)
return
modelo = self.obtener_modelo_seleccionado()
if not modelo:
self.mostrar_error("Error", "Selecciona un modelo.")
return
def tarea():
try:
self.label_estado_modelo.config(
text=f"Instalando {modelo}...",
foreground="orange"
)
subprocess.run(
[sys.executable, "-m", "spacy", "download", modelo],
check=True
)
self.label_estado_modelo.config(
text=f"Modelo {modelo} instalado correctamente.",
foreground="green"
)
except Exception as e:
self.label_estado_modelo.config(
text="Error al instalar el modelo.",
foreground="red"
)
self.mostrar_error(
"Error de instalación",
f"No se pudo instalar el modelo {modelo}.\n\nDetalle:\n{e}"
)
threading.Thread(target=tarea, daemon=True).start()
def cargar_modelo_en_hilo(self):
if not SPACY_INSTALADO:
self.mostrar_error(
"spaCy no instalado",
"Primero instala spaCy con:\n\npip install spacy"
)
return
modelo = self.obtener_modelo_seleccionado()
if not modelo:
self.mostrar_error("Error", "Selecciona un modelo.")
return
def tarea():
try:
self.label_estado_modelo.config(
text=f"Cargando {modelo}...",
foreground="orange"
)
self.nlp = spacy.load(modelo)
self.modelo_actual = modelo
self.label_estado_modelo.config(
text=f"Modelo cargado: {modelo}",
foreground="green"
)
except Exception as e:
self.nlp = None
self.modelo_actual = None
self.label_estado_modelo.config(
text="No se pudo cargar el modelo.",
foreground="red"
)
self.mostrar_error(
"Error al cargar modelo",
f"No se pudo cargar {modelo}.\n\n"
f"Primero instálalo con:\npython -m spacy download {modelo}\n\n"
f"Detalle:\n{e}"
)
threading.Thread(target=tarea, daemon=True).start()
def procesar_texto(self, texto):
if not self.asegurar_modelo_cargado():
return None
try:
return self.nlp(texto)
except Exception as e:
self.mostrar_error("Error al procesar texto", str(e))
return None
def cargar_ejemplo_es(self, widget):
widget.delete("1.0", tk.END)
widget.insert(tk.END, self.texto_es)
def cargar_ejemplo_en(self, widget):
widget.delete("1.0", tk.END)
widget.insert(tk.END, self.texto_en)
if __name__ == "__main__":
root = tk.Tk()
app = AplicacionSpaCy(root)
root.mainloop()La estructura del programa gira alrededor de una clase principal llamada AplicacionSpaCy. Allí se define el estado de la interfaz, el modelo cargado y los textos de ejemplo. A partir de esa base se construyen las pestañas y los controles que permiten probar distintas capacidades lingüísticas del pipeline.
La aplicación también deja ver varias ideas importantes de spaCy en un contexto práctico. Por un lado, muestra que trabajar con spaCy implica elegir y cargar un modelo lingüístico adecuado. Por otro, enseña que operaciones como tokenización, análisis del objeto Doc, extracción de entidades, dependencias y procesamiento por lotes pueden integrarse dentro de una herramienta interactiva en vez de quedar aisladas en scripts sueltos.
Además, el uso de hilos con threading.Thread(..., daemon=True) permite instalar modelos o procesar texto sin congelar la interfaz. Esa decisión es importante en aplicaciones reales, porque combina la riqueza del análisis lingüístico con una experiencia de uso más fluida.
18.25 Qué debes recordar de este tema
- spaCy es una biblioteca muy útil para procesamiento lingüístico eficiente en Python.
- Su concepto central es el pipeline de componentes aplicados sobre un documento.
- Destaca en tokenización, lematización, entidades y análisis estructurado del texto.
- Está especialmente orientada a aplicaciones prácticas y pipelines reales.
- No reemplaza por sí sola a todas las demás herramientas del ecosistema.
- Complementa muy bien a NLTK y a bibliotecas de modelado más moderno.
18.26 Conclusión
spaCy representa una forma más integrada y productiva de trabajar con NLP en Python. Su diseño orientado a pipelines, documentos enriquecidos y análisis estructurado la convierte en una herramienta especialmente valiosa cuando el objetivo es procesar texto real con eficiencia.
Entender spaCy también ayuda a ver cómo el ecosistema de NLP fue evolucionando desde herramientas más educativas hacia bibliotecas pensadas para integrarse mejor en sistemas concretos.
En el próximo tema estudiaremos la clasificación de texto con Machine Learning, conectando estas herramientas con uno de los problemas prácticos más importantes del NLP aplicado.