19. Clasificación de texto con Machine Learning
19.1 Introducción
Después de recorrer muchas técnicas de representación y herramientas del ecosistema Python, llegamos a uno de los problemas más clásicos y útiles del NLP aplicado: la clasificación de texto.
Clasificar texto significa tomar un documento, mensaje, correo, reseña o frase y asignarle una categoría. Es una tarea central porque aparece en muchísimos contextos reales: detección de spam, análisis de opiniones, clasificación temática, ruteo de tickets, filtrado de contenido y mucho más.
En este tema veremos cómo se plantea la clasificación de texto con Machine Learning clásico, qué etapas componen el pipeline y qué decisiones influyen en la calidad del sistema.
19.2 ¿Qué es exactamente clasificar texto?
Clasificar texto consiste en asignar una etiqueta a una unidad textual. Esa unidad puede ser:
- Una oración.
- Un comentario.
- Un correo electrónico.
- Una noticia.
- Un documento completo.
La etiqueta puede ser una categoría temática, un nivel de prioridad, una intención, una polaridad de sentimiento u otra clase definida por el problema.
19.3 Ejemplos cotidianos
Algunos ejemplos muy comunes de clasificación de texto son:
- Determinar si un correo es spam o no spam.
- Clasificar una noticia como deportes, política o economía.
- Decidir si una reseña es positiva o negativa.
- Asignar un ticket de soporte a facturación, técnico o comercial.
- Detectar si un mensaje contiene lenguaje ofensivo.
Todos estos casos comparten una misma estructura: texto de entrada y una etiqueta esperada como salida.
19.4 Tipos de clasificación
La clasificación de texto puede adoptar varias formas:
- Binaria: solo hay dos clases posibles.
- Multiclase: el texto pertenece a una sola clase entre varias.
- Multietiqueta: el texto puede pertenecer a varias clases al mismo tiempo.
Esta distinción es importante porque cambia el tipo de salida del modelo, la forma de entrenarlo y la manera de evaluarlo.
19.5 El pipeline clásico de clasificación
Un sistema clásico de clasificación de texto suele seguir una secuencia bastante clara:
- Recolección de textos etiquetados.
- Limpieza y preprocesamiento.
- Vectorización del texto.
- Entrenamiento del modelo.
- Evaluación sobre datos no vistos.
- Uso del modelo para clasificar nuevos textos.
Esta estructura parece simple, pero en cada etapa hay decisiones importantes que afectan el resultado final.
19.6 La importancia de los datos etiquetados
Para entrenar un clasificador supervisado necesitamos ejemplos ya etiquetados. Es decir, textos donde ya sepamos cuál es la clase correcta.
Por ejemplo:
- "No me llegó el pedido" → reclamo.
- "¿Cómo cambio mi contraseña?" → soporte.
- "Quiero dar de baja el servicio" → cancelación.
La calidad de estas etiquetas es crítica. Si los datos están mal etiquetados o no representan bien el problema real, el modelo aprenderá patrones incorrectos.
19.7 Preprocesamiento antes de clasificar
Antes de entrenar, el texto suele pasar por pasos de preprocesamiento como:
- Limpieza básica.
- Tokenización.
- Normalización.
- Stopwords, si la tarea lo justifica.
- Stemming o lematización en algunos casos.
La intensidad de este preprocesamiento depende del tipo de representación elegida y del problema. En Machine Learning clásico, estas decisiones suelen influir mucho más que en algunos modelos modernos.
19.8 Representación del texto para clasificar
Los modelos clásicos no operan directamente sobre texto crudo. Necesitan vectores numéricos. Las representaciones más frecuentes en este contexto suelen ser:
- Bag of Words.
- TF-IDF.
- En algunos casos, promedios de embeddings clásicos.
De estas, TF-IDF fue durante mucho tiempo una de las más efectivas y prácticas para clasificación de texto clásica.
19.9 Qué aprende realmente el modelo
Un clasificador de texto con Machine Learning no aprende "significados" en sentido humano. Aprende patrones estadísticos que relacionan ciertas representaciones del texto con ciertas clases.
Por ejemplo, puede aprender que palabras como gratis, oferta o urgente aparecen más a menudo en correos de spam, o que ciertos términos técnicos aparecen más en tickets de soporte.
Su utilidad depende de que esos patrones realmente generalicen a nuevos textos.
19.10 Modelos clásicos usados habitualmente
Entre los modelos más usados históricamente para clasificación de texto se encuentran:
- Naive Bayes.
- Regresión logística.
- Máquinas de soporte vectorial.
- Árboles y variantes basadas en árboles.
Todos ellos pueden trabajar bien con representaciones como Bag of Words o TF-IDF, aunque con comportamientos diferentes según el problema.
19.11 ¿Por qué estos modelos funcionaron tan bien?
Puede parecer sorprendente que modelos relativamente simples hayan sido tan efectivos durante años en clasificación de texto. La razón es que, en muchos problemas, la presencia y frecuencia de ciertos términos ya contiene mucha señal útil.
Si la tarea depende fuertemente de vocabulario temático o expresiones distintivas, un buen preprocesamiento más una representación sólida como TF-IDF puede ser suficiente para lograr resultados competitivos.
19.12 Separación entre entrenamiento y prueba
Un punto esencial en cualquier tarea supervisada es separar correctamente los datos de entrenamiento y de prueba. El modelo debe evaluarse sobre textos que no vio durante el entrenamiento.
Si no hacemos esto, podemos sobreestimar el rendimiento y creer que el sistema generaliza mejor de lo que realmente lo hace.
19.13 Evaluación del clasificador
Una vez entrenado el modelo, necesitamos medir qué tan bien clasifica textos nuevos. Para eso se usan métricas de evaluación. Entre las más comunes están:
- Accuracy.
- Precisión.
- Recall.
- F1-score.
La métrica adecuada depende del problema. En algunos casos, equivocarse en una clase puede ser mucho más costoso que equivocarse en otra.
19.14 El problema del desbalance de clases
En muchos datasets, algunas clases tienen muchísimos más ejemplos que otras. Esto se llama desbalance de clases y puede afectar mucho el entrenamiento.
Por ejemplo, si el 95% de los correos no son spam, un modelo ingenuo podría acertar mucho diciendo siempre "no spam", pero sería inútil en la práctica.
Por eso, al evaluar clasificadores de texto no alcanza con mirar una sola métrica global.
19.15 Ejemplo conceptual completo
Supongamos que queremos clasificar reseñas de productos como positivas o negativas.
- Reunimos muchas reseñas etiquetadas.
- Preprocesamos y vectorizamos el texto con TF-IDF.
- Entrenamos un clasificador.
- Evaluamos el modelo sobre reseñas no vistas.
- Usamos el sistema para clasificar nuevas opiniones.
Este ejemplo resume la lógica básica de muchísimos sistemas de clasificación textual en la práctica.
19.16 Errores comunes en clasificación de texto
Algunos errores muy frecuentes en este tipo de proyectos son:
- Datos mal etiquetados.
- Preprocesamiento inconsistente entre entrenamiento e inferencia.
- Evaluar con datos filtrados o mal divididos.
- Ignorar el desbalance de clases.
- Confiar demasiado en accuracy sin analizar errores reales.
Muchas veces, el problema no está en el algoritmo elegido sino en la calidad del pipeline completo.
19.17 Clasificación temática versus análisis de sentimiento
Aunque ambas tareas son clasificación de texto, no son exactamente lo mismo. En clasificación temática el objetivo suele ser detectar de qué trata un texto. En análisis de sentimiento, en cambio, el foco está en la polaridad o actitud expresada.
Esto es importante porque la señal útil puede ser distinta:
- En clasificación temática suelen importar más los términos de contenido.
- En sentimiento pueden ser críticas las negaciones, intensificadores y matices de tono.
19.18 Interpretabilidad en modelos clásicos
Una ventaja de muchos clasificadores clásicos es que resultan relativamente interpretables. A menudo puede inspeccionarse qué palabras o características pesan más en una decisión.
Esto es útil porque permite detectar:
- Sesgos del dataset.
- Palabras espurias aprendidas por el modelo.
- Señales verdaderamente informativas.
En proyectos reales, esta interpretabilidad puede ser una gran ventaja frente a métodos más opacos.
19.19 Cuándo sigue siendo una buena opción
La clasificación de texto con Machine Learning clásico sigue siendo muy buena opción cuando:
- Se necesita una baseline fuerte y rápida.
- El problema está bien delimitado.
- La cantidad de datos no justifica un modelo profundo complejo.
- La interpretabilidad es importante.
- Se busca una solución eficiente y relativamente simple.
19.20 Relación con Deep Learning
Más adelante veremos modelos neuronales para texto. Pero es importante entender que Deep Learning no vuelve obsoleta toda clasificación clásica. En muchos problemas, un pipeline bien hecho con TF-IDF y un clasificador tradicional puede rendir sorprendentemente bien.
Por eso, conocer este enfoque sigue siendo muy valioso incluso en el contexto actual.
19.21 Resumen del pipeline
| Etapa | Qué se hace | Ejemplo |
|---|---|---|
| Datos | Se reúnen textos etiquetados. | Correos spam y no spam. |
| Preprocesamiento | Se limpia y normaliza el texto. | Tokenización y TF-IDF. |
| Entrenamiento | Se ajusta un clasificador supervisado. | Regresión logística o SVM. |
| Evaluación | Se mide rendimiento en datos no vistos. | F1-score, precisión, recall. |
| Inferencia | Se clasifican nuevos textos. | Ruteo automático de tickets. |
19.22 Ejemplo en Python: clasificar tickets con scikit-learn
Este ejemplo entrena un clasificador pequeño para enrutar tickets de soporte. Es interesante porque se parece bastante a un problema real de negocio y muestra el pipeline clásico completo en muy pocas líneas.
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
textos = [
"no puedo iniciar sesion en mi cuenta",
"quiero cambiar el metodo de pago",
"la factura tiene un importe incorrecto",
"la aplicacion se cierra al abrir un reporte",
"necesito actualizar la tarjeta de credito",
"el sistema arroja error al exportar"
]
etiquetas = ["tecnico", "facturacion", "facturacion", "tecnico", "facturacion", "tecnico"]
modelo = Pipeline([
("tfidf", TfidfVectorizer(ngram_range=(1, 2))),
("clf", LogisticRegression(max_iter=1000))
])
modelo.fit(textos, etiquetas)
pruebas = [
"error al iniciar la aplicacion",
"quiero descargar una nueva factura"
]
print(modelo.predict(pruebas))Este tipo de ejemplo muestra por qué la clasificación de texto clásica sigue siendo tan útil: con buenos datos y una representación razonable, puede resolver tareas de automatización con muy poco costo operativo.
19.23 Ejemplo en Python: aplicación de escritorio para clasificar spam con Machine Learning
El objetivo de este ejemplo es construir una aplicación completa de clasificación de texto sobre un problema clásico: distinguir mensajes spam de mensajes normales. En lugar de mostrar solo unas pocas líneas de entrenamiento, el programa reúne en una interfaz gráfica todo el flujo de trabajo de un sistema real: descarga del dataset, exploración de datos, entrenamiento con TF-IDF y regresión logística, evaluación con métricas, análisis de errores, clasificación de mensajes nuevos y guardado del modelo.
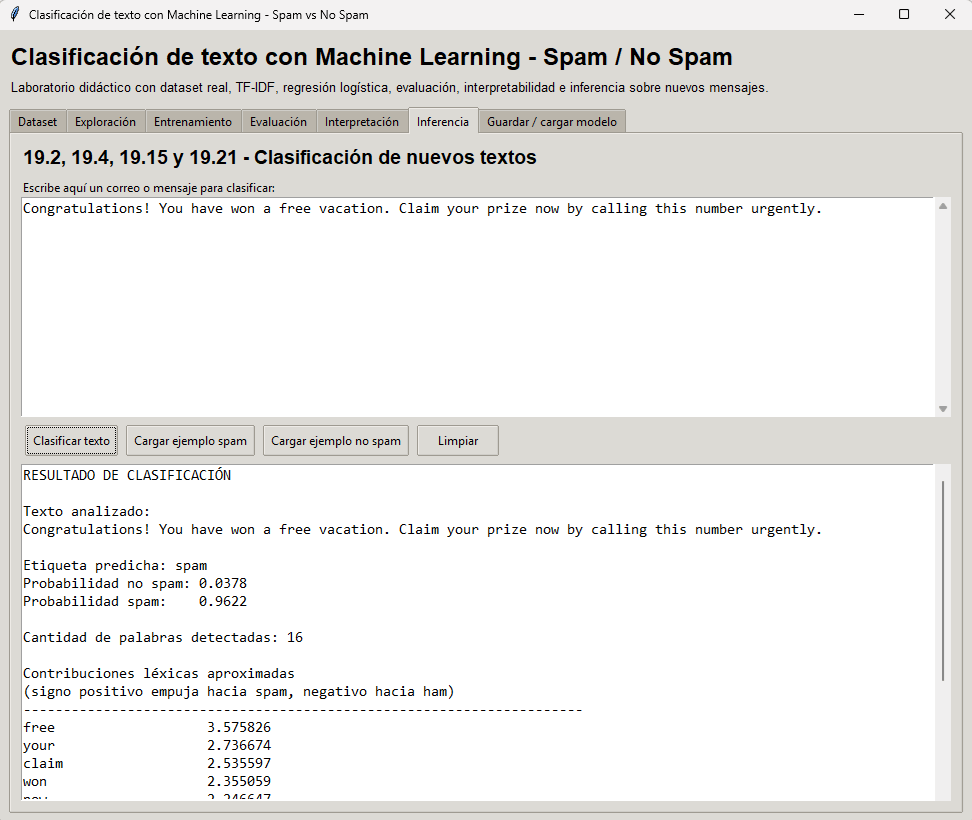
Eso lo vuelve especialmente útil desde el punto de vista didáctico, porque permite ver cómo se conectan entre sí las distintas etapas de un pipeline supervisado de NLP clásico.
import os
import io
import re
import zipfile
import pickle
import random
import threading
import urllib.request
import tkinter as tk
from tkinter import ttk, messagebox
from tkinter.scrolledtext import ScrolledText
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
confusion_matrix,
classification_report,
)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
class AplicacionClasificacionSpam:
def __init__(self, root):
self.root = root
self.root.title("Clasificacion de texto con Machine Learning - Spam vs No Spam")
self.root.geometry("1650x980")
self.carpeta_app = "clasificador_spam_app"
self.carpeta_datos = os.path.join(self.carpeta_app, "datos")
self.archivo_zip = os.path.join(self.carpeta_datos, "sms_spam_collection.zip")
self.archivo_dataset = os.path.join(self.carpeta_datos, "SMSSpamCollection")
self.archivo_modelo = os.path.join(self.carpeta_datos, "modelo_spam.pkl")
os.makedirs(self.carpeta_datos, exist_ok=True)
self.df = None
self.pipeline = None
self.vectorizador = None
self.clasificador = None
self.X_train = None
self.X_test = None
self.y_train = None
self.y_test = None
self.entrenando = False
self.texto_demo_spam = (
"Congratulations! You have won a free vacation. "
"Claim your prize now by calling this number urgently."
)
self.texto_demo_ham = (
"Hola, te escribo para confirmar la reunion de manana a las 10. "
"Avisame si te queda bien el horario."
)
self.crear_interfaz()
def crear_interfaz(self):
estilo = ttk.Style()
try:
estilo.theme_use("clam")
except:
pass
contenedor = ttk.Frame(self.root, padding=10)
contenedor.pack(fill="both", expand=True)
cabecera = ttk.Frame(contenedor)
cabecera.pack(fill="x", pady=(0, 10))
ttk.Label(
cabecera,
text="Clasificacion de texto con Machine Learning - Spam / No Spam",
font=("Arial", 18, "bold")
).pack(anchor="w")
ttk.Label(
cabecera,
text=(
"Laboratorio didactico con dataset real, TF-IDF, regresion logistica, "
"evaluacion, interpretabilidad e inferencia sobre nuevos mensajes."
),
font=("Arial", 10)
).pack(anchor="w", pady=(4, 0))
self.notebook = ttk.Notebook(contenedor)
self.notebook.pack(fill="both", expand=True)
self.crear_pestana_dataset()
self.crear_pestana_exploracion()
self.crear_pestana_entrenamiento()
self.crear_pestana_evaluacion()
self.crear_pestana_interpretacion()
self.crear_pestana_inferencia()
self.crear_pestana_modelo()
def insertar_texto(self, widget, texto):
widget.config(state="normal")
widget.delete("1.0", tk.END)
widget.insert(tk.END, texto)
widget.config(state="normal")
def obtener_texto(self, widget):
return widget.get("1.0", tk.END).strip()
def limpiar_texto_basico(self, texto):
texto = texto.lower()
texto = re.sub(r"\s+", " ", texto)
return texto.strip()
def mostrar_error(self, titulo, mensaje):
messagebox.showerror(titulo, mensaje)
def mostrar_info(self, titulo, mensaje):
messagebox.showinfo(titulo, mensaje)
def asegurar_dataset_cargado(self):
if self.df is None or len(self.df) == 0:
self.mostrar_error("Dataset no cargado", "Primero debes descargar/cargar el dataset.")
return False
return True
def asegurar_modelo_entrenado(self):
if self.pipeline is None:
self.mostrar_error("Modelo no entrenado", "Primero debes entrenar o cargar un modelo.")
return False
return True
# =========================================================
# PESTANA 1 - DATASET
# =========================================================
def crear_pestana_dataset(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Dataset")
izquierda = ttk.Frame(tab)
izquierda.pack(side="left", fill="both", expand=True, padx=(0, 8))
derecha = ttk.Frame(tab)
derecha.pack(side="left", fill="both", expand=True)
ttk.Label(
izquierda,
text="19.5, 19.6 y 19.21 - Datos etiquetados y preparacion del problema",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
texto = (
"Esta aplicacion trabaja con un dataset de mensajes etiquetados como spam o ham.\n\n"
"ham = mensaje normal / no spam\n"
"spam = mensaje no deseado\n\n"
"Flujo didactico:\n"
"1. Descargar dataset\n"
"2. Cargarlo en un DataFrame\n"
"3. Explorar ejemplos\n"
"4. Entrenar un pipeline TF-IDF + clasificador\n"
"5. Evaluar en datos no vistos\n"
"6. Escribir nuevos mensajes y clasificarlos\n"
)
self.txt_info_dataset = ScrolledText(izquierda, wrap="word", font=("Consolas", 11), height=28)
self.txt_info_dataset.pack(fill="both", expand=True)
self.txt_info_dataset.insert(tk.END, texto)
ttk.Label(
derecha,
text="Operaciones sobre el dataset",
font=("Arial", 13, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Button(
derecha,
text="Descargar dataset real y cargarlo",
command=self.descargar_y_cargar_dataset_en_hilo
).pack(fill="x", pady=4)
ttk.Button(
derecha,
text="Cargar dataset local si ya existe",
command=self.cargar_dataset_local
).pack(fill="x", pady=4)
ttk.Button(
derecha,
text="Mostrar resumen del dataset",
command=self.mostrar_resumen_dataset
).pack(fill="x", pady=4)
self.label_estado_dataset = ttk.Label(
derecha,
text="Estado: dataset no cargado.",
foreground="blue"
)
self.label_estado_dataset.pack(anchor="w", pady=(15, 0))
self.txt_dataset_estado = ScrolledText(derecha, wrap="word", font=("Consolas", 11), height=18)
self.txt_dataset_estado.pack(fill="both", expand=True, pady=(10, 0))
def descargar_y_cargar_dataset_en_hilo(self):
def tarea():
try:
self.label_estado_dataset.config(text="Descargando dataset...", foreground="orange")
urls = [
"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip",
"https://raw.githubusercontent.com/justmarkham/pycon-2016-tutorial/master/data/sms.tsv",
]
descargado = False
ultimo_error = None
for url in urls:
try:
if url.endswith(".zip"):
urllib.request.urlretrieve(url, self.archivo_zip)
with zipfile.ZipFile(self.archivo_zip, "r") as zf:
for nombre in zf.namelist():
if nombre.endswith("SMSSpamCollection"):
zf.extract(nombre, self.carpeta_datos)
ruta_extraida = os.path.join(self.carpeta_datos, nombre)
if ruta_extraida != self.archivo_dataset:
if os.path.exists(self.archivo_dataset):
os.remove(self.archivo_dataset)
os.replace(ruta_extraida, self.archivo_dataset)
descargado = True
break
if descargado:
break
else:
ruta_tsv = os.path.join(self.carpeta_datos, "sms.tsv")
urllib.request.urlretrieve(url, ruta_tsv)
df = pd.read_csv(ruta_tsv, sep="\t", header=None, names=["label", "text"])
df.to_csv(self.archivo_dataset, sep="\t", index=False, header=False)
descargado = True
break
except Exception as e:
ultimo_error = e
if not descargado:
raise RuntimeError(f"No se pudo descargar el dataset. Ultimo error: {ultimo_error}")
self.cargar_dataset_desde_archivo(self.archivo_dataset)
self.label_estado_dataset.config(
text=f"Dataset cargado correctamente. Registros: {len(self.df)}",
foreground="green"
)
self.mostrar_resumen_dataset()
except Exception as e:
self.label_estado_dataset.config(text="Error al descargar/cargar dataset.", foreground="red")
self.mostrar_error("Error", str(e))
threading.Thread(target=tarea, daemon=True).start()
def cargar_dataset_local(self):
try:
if not os.path.exists(self.archivo_dataset):
self.mostrar_error(
"Archivo inexistente",
"No se encontro el dataset local. Usa primero 'Descargar dataset real y cargarlo'."
)
return
self.cargar_dataset_desde_archivo(self.archivo_dataset)
self.label_estado_dataset.config(
text=f"Dataset local cargado. Registros: {len(self.df)}",
foreground="green"
)
self.mostrar_resumen_dataset()
except Exception as e:
self.mostrar_error("Error", str(e))
def cargar_dataset_desde_archivo(self, ruta):
df = pd.read_csv(ruta, sep="\t", header=None, names=["label", "text"], encoding="utf-8")
df["label"] = df["label"].astype(str).str.strip().str.lower()
df["text"] = df["text"].astype(str)
df = df[df["label"].isin(["ham", "spam"])].copy()
df["label_num"] = df["label"].map({"ham": 0, "spam": 1})
df["text_clean"] = df["text"].apply(self.limpiar_texto_basico)
df["length"] = df["text"].apply(len)
df["num_words"] = df["text"].apply(lambda x: len(x.split()))
self.df = df.reset_index(drop=True)
def mostrar_resumen_dataset(self):
if not self.asegurar_dataset_cargado():
return
total = len(self.df)
cant_spam = int((self.df["label"] == "spam").sum())
cant_ham = int((self.df["label"] == "ham").sum())
salida = "RESUMEN DEL DATASET\n\n"
salida += f"Cantidad total de mensajes: {total}\n"
salida += f"No spam (ham): {cant_ham}\n"
salida += f"Spam: {cant_spam}\n\n"
salida += "Porcentajes:\n"
salida += f"Ham: {cant_ham / total * 100:.2f}%\n"
salida += f"Spam: {cant_spam / total * 100:.2f}%\n\n"
salida += "Primeras filas:\n"
salida += "-" * 80 + "\n"
for i, fila in self.df.head(8).iterrows():
texto = fila["text"].replace("\n", " ")
if len(texto) > 90:
texto = texto[:90] + "..."
salida += f"{i+1:>2}. [{fila['label']}] {texto}\n"
self.insertar_texto(self.txt_dataset_estado, salida)
# =========================================================
# PESTANA 2 - EXPLORACION
# =========================================================
def crear_pestana_exploracion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Exploracion")
ttk.Label(
tab,
text="19.3, 19.7 y 19.14 - Exploracion, preprocesamiento y desbalance",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Mostrar ejemplos aleatorios", command=self.mostrar_ejemplos_aleatorios).pack(side="left", padx=4)
ttk.Button(controles, text="Estadisticas de longitud", command=self.mostrar_estadisticas_longitud).pack(side="left", padx=4)
ttk.Button(controles, text="Ver palabras frecuentes por clase", command=self.mostrar_palabras_frecuentes_basicas).pack(side="left", padx=4)
self.txt_exploracion = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=32)
self.txt_exploracion.pack(fill="both", expand=True)
def mostrar_ejemplos_aleatorios(self):
if not self.asegurar_dataset_cargado():
return
spam_df = self.df[self.df["label"] == "spam"].sample(min(5, len(self.df[self.df["label"] == "spam"])), random_state=random.randint(1, 10000))
ham_df = self.df[self.df["label"] == "ham"].sample(min(5, len(self.df[self.df["label"] == "ham"])), random_state=random.randint(1, 10000))
salida = "EJEMPLOS ALEATORIOS\n\n"
salida += "MENSAJES NO SPAM (HAM)\n"
salida += "-" * 70 + "\n"
for _, fila in ham_df.iterrows():
salida += f"- {fila['text']}\n\n"
salida += "\nMENSAJES SPAM\n"
salida += "-" * 70 + "\n"
for _, fila in spam_df.iterrows():
salida += f"- {fila['text']}\n\n"
self.insertar_texto(self.txt_exploracion, salida)
def mostrar_estadisticas_longitud(self):
if not self.asegurar_dataset_cargado():
return
salida = "ESTADISTICAS DE LONGITUD\n\n"
for clase in ["ham", "spam"]:
sub = self.df[self.df["label"] == clase]
salida += f"Clase: {clase}\n"
salida += f"Cantidad: {len(sub)}\n"
salida += f"Promedio de caracteres: {sub['length'].mean():.2f}\n"
salida += f"Promedio de palabras: {sub['num_words'].mean():.2f}\n"
salida += f"Minimo de palabras: {sub['num_words'].min()}\n"
salida += f"Maximo de palabras: {sub['num_words'].max()}\n"
salida += "-" * 60 + "\n"
self.insertar_texto(self.txt_exploracion, salida)
def mostrar_palabras_frecuentes_basicas(self):
if not self.asegurar_dataset_cargado():
return
salida = "PALABRAS FRECUENTES BASICAS POR CLASE\n\n"
for clase in ["ham", "spam"]:
sub = self.df[self.df["label"] == clase]
texto_total = " ".join(sub["text_clean"].tolist())
palabras = re.findall(r"\b[a-zA-Z0-9']+\b", texto_total)
conteo = {}
for p in palabras:
if len(p) >= 3:
conteo[p] = conteo.get(p, 0) + 1
top = sorted(conteo.items(), key=lambda x: x[1], reverse=True)[:30]
salida += f"CLASE: {clase}\n"
salida += "-" * 60 + "\n"
for palabra, freq in top:
salida += f"{palabra:<20} {freq}\n"
salida += "\n"
self.insertar_texto(self.txt_exploracion, salida)
# =========================================================
# PESTANA 3 - ENTRENAMIENTO
# =========================================================
def crear_pestana_entrenamiento(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Entrenamiento")
ttk.Label(
tab,
text="19.8, 19.10, 19.11 y 19.12 - TF-IDF, modelo y separacion train/test",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Label(controles, text="Test size:").pack(side="left", padx=(0, 5))
self.entry_test_size = ttk.Entry(controles, width=8)
self.entry_test_size.pack(side="left")
self.entry_test_size.insert(0, "0.25")
ttk.Label(controles, text="max_features TF-IDF:").pack(side="left", padx=(15, 5))
self.entry_max_features = ttk.Entry(controles, width=10)
self.entry_max_features.pack(side="left")
self.entry_max_features.insert(0, "5000")
ttk.Checkbutton(
controles,
text="Usar ngram_range=(1,2)",
variable=tk.BooleanVar(value=True),
)
self.var_bigrama = tk.BooleanVar(value=True)
ttk.Checkbutton(
controles,
text="Usar ngram_range=(1,2)",
variable=self.var_bigrama
).pack(side="left", padx=10)
ttk.Button(controles, text="Entrenar modelo", command=self.entrenar_modelo_en_hilo).pack(side="left", padx=8)
self.label_estado_entrenamiento = ttk.Label(
controles,
text="Estado: modelo no entrenado.",
foreground="blue"
)
self.label_estado_entrenamiento.pack(side="left", padx=12)
self.txt_entrenamiento = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=30)
self.txt_entrenamiento.pack(fill="both", expand=True)
def entrenar_modelo_en_hilo(self):
if not self.asegurar_dataset_cargado():
return
if self.entrenando:
return
def tarea():
try:
self.entrenando = True
self.label_estado_entrenamiento.config(text="Entrenando modelo...", foreground="orange")
test_size = float(self.entry_test_size.get())
max_features = int(self.entry_max_features.get())
usar_bigramas = self.var_bigrama.get()
X = self.df["text_clean"]
y = self.df["label_num"]
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
X, y,
test_size=test_size,
random_state=42,
stratify=y
)
ngram = (1, 2) if usar_bigramas else (1, 1)
self.pipeline = Pipeline([
("tfidf", TfidfVectorizer(
lowercase=True,
strip_accents="unicode",
max_features=max_features,
ngram_range=ngram,
min_df=1
)),
("clf", LogisticRegression(
max_iter=2000,
solver="liblinear",
class_weight="balanced"
))
])
self.pipeline.fit(self.X_train, self.y_train)
self.vectorizador = self.pipeline.named_steps["tfidf"]
self.clasificador = self.pipeline.named_steps["clf"]
salida = "ENTRENAMIENTO COMPLETADO\n\n"
salida += f"Registros totales: {len(self.df)}\n"
salida += f"Entrenamiento: {len(self.X_train)}\n"
salida += f"Prueba: {len(self.X_test)}\n\n"
salida += "Pipeline utilizado:\n"
salida += "- Vectorizacion: TF-IDF\n"
salida += f"- max_features: {max_features}\n"
salida += f"- ngram_range: {ngram}\n"
salida += "- Clasificador: LogisticRegression\n"
salida += "- class_weight: balanced\n"
salida += "- solver: liblinear\n"
self.insertar_texto(self.txt_entrenamiento, salida)
self.label_estado_entrenamiento.config(text="Modelo entrenado correctamente.", foreground="green")
except Exception as e:
self.label_estado_entrenamiento.config(text="Error en entrenamiento.", foreground="red")
self.mostrar_error("Error", str(e))
finally:
self.entrenando = False
threading.Thread(target=tarea, daemon=True).start()
# =========================================================
# PESTANA 4 - EVALUACION
# =========================================================
def crear_pestana_evaluacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Evaluacion")
ttk.Label(
tab,
text="19.13, 19.14 y 19.16 - Metricas, desbalance y errores",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Evaluar modelo", command=self.evaluar_modelo).pack(side="left", padx=4)
ttk.Button(controles, text="Mostrar errores de prueba", command=self.mostrar_errores_prueba).pack(side="left", padx=4)
self.txt_evaluacion = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=30)
self.txt_evaluacion.pack(fill="both", expand=True)
def evaluar_modelo(self):
if not self.asegurar_modelo_entrenado():
return
try:
y_pred = self.pipeline.predict(self.X_test)
acc = accuracy_score(self.y_test, y_pred)
prec = precision_score(self.y_test, y_pred, zero_division=0)
rec = recall_score(self.y_test, y_pred, zero_division=0)
f1 = f1_score(self.y_test, y_pred, zero_division=0)
cm = confusion_matrix(self.y_test, y_pred)
salida = "EVALUACION DEL CLASIFICADOR\n\n"
salida += f"Accuracy : {acc:.4f}\n"
salida += f"Precision: {prec:.4f}\n"
salida += f"Recall : {rec:.4f}\n"
salida += f"F1-score : {f1:.4f}\n\n"
salida += "Matriz de confusion\n"
salida += "Filas = reales, Columnas = predichas\n\n"
salida += " Pred ham Pred spam\n"
salida += f"Real ham {cm[0,0]:>10} {cm[0,1]:>12}\n"
salida += f"Real spam {cm[1,0]:>10} {cm[1,1]:>12}\n\n"
salida += "Classification report\n"
salida += "-" * 70 + "\n"
salida += classification_report(
self.y_test,
y_pred,
target_names=["ham", "spam"],
zero_division=0
)
self.insertar_texto(self.txt_evaluacion, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
def mostrar_errores_prueba(self):
if not self.asegurar_modelo_entrenado():
return
try:
y_pred = self.pipeline.predict(self.X_test)
probs = self.pipeline.predict_proba(self.X_test)
errores = []
for idx, (texto, real, pred, pr) in enumerate(zip(self.X_test.tolist(), self.y_test.tolist(), y_pred.tolist(), probs.tolist())):
if real != pred:
prob_spam = pr[1]
errores.append((texto, real, pred, prob_spam))
salida = "ERRORES SOBRE EL CONJUNTO DE PRUEBA\n\n"
salida += f"Cantidad de errores: {len(errores)}\n\n"
if not errores:
salida += "No hubo errores en el conjunto de prueba."
else:
for i, (texto, real, pred, prob_spam) in enumerate(errores[:20], start=1):
texto_corto = texto if len(texto) < 220 else texto[:220] + "..."
salida += f"Error {i}\n"
salida += f"Real: {'spam' if real == 1 else 'ham'}\n"
salida += f"Pred: {'spam' if pred == 1 else 'ham'}\n"
salida += f"Probabilidad spam: {prob_spam:.4f}\n"
salida += f"Texto: {texto_corto}\n"
salida += "-" * 80 + "\n"
self.insertar_texto(self.txt_evaluacion, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
# =========================================================
# PESTANA 5 - INTERPRETACION
# =========================================================
def crear_pestana_interpretacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Interpretacion")
ttk.Label(
tab,
text="19.18 y 19.19 - Interpretabilidad y baseline clasico",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Mostrar terminos mas spam", command=self.mostrar_terminos_mas_spam).pack(side="left", padx=4)
ttk.Button(controles, text="Mostrar terminos mas ham", command=self.mostrar_terminos_mas_ham).pack(side="left", padx=4)
self.txt_interpretacion = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=30)
self.txt_interpretacion.pack(fill="both", expand=True)
def mostrar_terminos_mas_spam(self):
self.mostrar_terminos_por_peso(clase_objetivo="spam")
def mostrar_terminos_mas_ham(self):
self.mostrar_terminos_por_peso(clase_objetivo="ham")
def mostrar_terminos_por_peso(self, clase_objetivo="spam"):
if not self.asegurar_modelo_entrenado():
return
try:
vocab = self.vectorizador.get_feature_names_out()
coef = self.clasificador.coef_[0]
if clase_objetivo == "spam":
indices = coef.argsort()[-40:][::-1]
titulo = "TERMINOS CON MAYOR PESO HACIA SPAM"
else:
indices = coef.argsort()[:40]
titulo = "TERMINOS CON MAYOR PESO HACIA HAM / NO SPAM"
salida = titulo + "\n\n"
salida += f"{'TERMINO':<30}{'PESO':>12}\n"
salida += "-" * 45 + "\n"
for idx in indices:
salida += f"{vocab[idx]:<30}{coef[idx]:>12.6f}\n"
self.insertar_texto(self.txt_interpretacion, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
# =========================================================
# PESTANA 6 - INFERENCIA
# =========================================================
def crear_pestana_inferencia(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Inferencia")
ttk.Label(
tab,
text="19.2, 19.4, 19.15 y 19.21 - Clasificacion de nuevos textos",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Escribe aqui un correo o mensaje para clasificar:").pack(anchor="w")
self.txt_inferencia_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_inferencia_entrada.pack(fill="x", pady=(0, 8))
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_spam)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Clasificar texto", command=self.clasificar_texto_personalizado).pack(side="left", padx=4)
ttk.Button(controles, text="Cargar ejemplo spam", command=self.cargar_demo_spam).pack(side="left", padx=4)
ttk.Button(controles, text="Cargar ejemplo no spam", command=self.cargar_demo_ham).pack(side="left", padx=4)
ttk.Button(controles, text="Limpiar", command=lambda: self.txt_inferencia_entrada.delete("1.0", tk.END)).pack(side="left", padx=4)
self.txt_inferencia_salida = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=25)
self.txt_inferencia_salida.pack(fill="both", expand=True)
def cargar_demo_spam(self):
self.txt_inferencia_entrada.delete("1.0", tk.END)
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_spam)
def cargar_demo_ham(self):
self.txt_inferencia_entrada.delete("1.0", tk.END)
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_ham)
def clasificar_texto_personalizado(self):
if not self.asegurar_modelo_entrenado():
return
texto = self.obtener_texto(self.txt_inferencia_entrada)
if not texto:
self.mostrar_error("Error", "Debes escribir un texto.")
return
try:
texto_limpio = self.limpiar_texto_basico(texto)
pred = self.pipeline.predict([texto_limpio])[0]
probs = self.pipeline.predict_proba([texto_limpio])[0]
etiqueta = "spam" if pred == 1 else "ham / no spam"
prob_ham = probs[0]
prob_spam = probs[1]
salida = "RESULTADO DE CLASIFICACION\n\n"
salida += f"Texto analizado:\n{texto}\n\n"
salida += f"Etiqueta predicha: {etiqueta}\n"
salida += f"Probabilidad no spam: {prob_ham:.4f}\n"
salida += f"Probabilidad spam: {prob_spam:.4f}\n\n"
palabras = re.findall(r"\b[a-zA-Z0-9']+\b", texto_limpio)
salida += f"Cantidad de palabras detectadas: {len(palabras)}\n\n"
if hasattr(self.clasificador, "coef_"):
vocab = self.vectorizador.vocabulary_
coef = self.clasificador.coef_[0]
contribuciones = []
for p in palabras:
if p in vocab:
idx = vocab[p]
contribuciones.append((p, coef[idx]))
if contribuciones:
salida += "Contribuciones lexicas aproximadas\n"
salida += "(signo positivo empuja hacia spam, negativo hacia ham)\n"
salida += "-" * 70 + "\n"
for palabra, peso in sorted(contribuciones, key=lambda x: abs(x[1]), reverse=True)[:20]:
salida += f"{palabra:<20} {peso:>10.6f}\n"
else:
salida += "No hubo terminos del mensaje presentes en el vocabulario del modelo."
self.insertar_texto(self.txt_inferencia_salida, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
# =========================================================
# PESTANA 7 - MODELO
# =========================================================
def crear_pestana_modelo(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Guardar / cargar modelo")
ttk.Label(
tab,
text="Persistencia del pipeline entrenado",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Button(tab, text="Guardar modelo entrenado", command=self.guardar_modelo).pack(anchor="w", pady=4)
ttk.Button(tab, text="Cargar modelo guardado", command=self.cargar_modelo_guardado).pack(anchor="w", pady=4)
self.txt_modelo = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=28)
self.txt_modelo.pack(fill="both", expand=True, pady=(10, 0))
def guardar_modelo(self):
if not self.asegurar_modelo_entrenado():
return
try:
with open(self.archivo_modelo, "wb") as f:
pickle.dump({
"pipeline": self.pipeline
}, f)
salida = "MODELO GUARDADO\n\n"
salida += f"Ruta: {self.archivo_modelo}\n"
salida += "Se guardo el pipeline completo: TF-IDF + LogisticRegression.\n"
self.insertar_texto(self.txt_modelo, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
def cargar_modelo_guardado(self):
try:
if not os.path.exists(self.archivo_modelo):
self.mostrar_error("Archivo inexistente", "No existe un modelo guardado todavia.")
return
with open(self.archivo_modelo, "rb") as f:
datos = pickle.load(f)
self.pipeline = datos["pipeline"]
self.vectorizador = self.pipeline.named_steps["tfidf"]
self.clasificador = self.pipeline.named_steps["clf"]
salida = "MODELO CARGADO\n\n"
salida += f"Ruta: {self.archivo_modelo}\n"
salida += "El modelo quedo listo para clasificar nuevos mensajes.\n"
self.insertar_texto(self.txt_modelo, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
if __name__ == "__main__":
root = tk.Tk()
app = AplicacionClasificacionSpam(root)
root.mainloop()La estructura del programa está pensada para que cada pestaña represente una etapa del pipeline. Primero se cargan y exploran los datos; después se entrena el modelo; luego se evalúa su comportamiento; más tarde se inspeccionan términos relevantes y finalmente se usa el clasificador sobre mensajes nuevos. Esa organización ayuda a entender que la clasificación de texto no es una sola operación aislada, sino un proceso completo.
Además, el ejemplo deja ver varias decisiones típicas del NLP clásico. El texto se normaliza de forma básica, se vectoriza con TfidfVectorizer, se entrena una LogisticRegression dentro de un Pipeline y se miden métricas como accuracy, precision, recall y F1. Por eso funciona muy bien como puente entre teoría y una implementación práctica más cercana a una aplicación real.
19.24 Qué debes recordar de este tema
- La clasificación de texto asigna etiquetas a documentos, mensajes o frases.
- Puede ser binaria, multiclase o multietiqueta.
- En Machine Learning clásico suele usarse junto con Bag of Words o TF-IDF.
- La calidad del pipeline depende tanto de los datos como del modelo.
- La evaluación correcta y el manejo del desbalance son fundamentales.
- Sigue siendo un enfoque muy útil en muchos problemas reales.
19.25 Conclusión
La clasificación de texto con Machine Learning es una de las aplicaciones más directas, útiles e históricamente exitosas del NLP. Resume muy bien la lógica clásica del área: representar texto, entrenar un modelo supervisado y usarlo para tomar decisiones sobre nuevos documentos.
Comprender este pipeline es clave porque conecta muchos conceptos que vimos hasta ahora y prepara el terreno para comparar enfoques clásicos con enfoques más modernos.
En el próximo tema estudiaremos el análisis de sentimiento, un caso particular de clasificación textual que introducirá nuevos matices relacionados con tono, negación y polaridad.