20. Análisis de sentimiento
20.1 Introducción
Entre las aplicaciones más conocidas del Procesamiento de Lenguaje Natural se encuentra el análisis de sentimiento, también llamado en muchos contextos sentiment analysis u opinion mining.
La idea general parece simple: leer un texto y determinar si expresa una opinión positiva, negativa o neutral. Sin embargo, en la práctica se trata de una tarea mucho más sutil, porque las opiniones humanas no siempre son directas, consistentes ni fáciles de interpretar.
En este tema veremos qué es exactamente el análisis de sentimiento, por qué puede plantearse como un problema de clasificación de texto y qué dificultades especiales introduce.
20.2 ¿Qué es el análisis de sentimiento?
El análisis de sentimiento consiste en identificar la carga afectiva u opinativa de un texto. En otras palabras, intenta responder preguntas como estas:
- ¿La opinión expresada es favorable o desfavorable?
- ¿El tono general es positivo, negativo o neutral?
- ¿La intensidad del juicio es suave o muy marcada?
- ¿La opinión se refiere al objeto completo o a una parte específica?
No todos los textos contienen opiniones. Una oración como "El producto fue entregado el lunes" informa un hecho. En cambio, "El producto llegó tarde y la calidad fue decepcionante" ya expresa una evaluación subjetiva.
20.3 Polaridad básica
La forma más simple de análisis de sentimiento trabaja con la idea de polaridad. La polaridad resume la orientación emocional principal del texto.
- Positiva: expresa aprobación, satisfacción o valoración favorable.
- Negativa: expresa rechazo, frustración o valoración desfavorable.
- Neutral: no expresa una opinión clara o mezcla información sin juicio marcado.
Por ejemplo, una reseña como "La aplicación funciona muy bien y la interfaz es clara" suele clasificarse como positiva. En cambio, "Se cierra sola y pierde mis datos" suele clasificarse como negativa.
20.4 Un caso particular de clasificación de texto
Desde el punto de vista técnico, el análisis de sentimiento puede verse como un problema de clasificación supervisada. La entrada es un texto y la salida es una etiqueta asociada al sentimiento.
Eso significa que muchos conceptos del tema anterior se aplican aquí de manera directa:
- Necesitamos datos etiquetados.
- Debemos transformar el texto en vectores numéricos.
- Entrenamos un modelo con ejemplos previos.
- Evaluamos el desempeño en datos no vistos.
La diferencia es que ahora la etiqueta no representa un tema o una categoría funcional, sino una valoración subjetiva.
20.5 Ejemplos cotidianos
El análisis de sentimiento aparece en muchísimos contextos reales:
- Reseñas de productos en tiendas en línea.
- Comentarios en redes sociales.
- Opiniones sobre películas, libros o restaurantes.
- Encuestas de satisfacción de clientes.
- Mensajes enviados a soporte técnico.
En todos estos casos interesa resumir automáticamente la percepción general de las personas, especialmente cuando el volumen de texto es demasiado grande para analizarlo manualmente.
20.6 ¿Por qué es útil?
El valor del análisis de sentimiento no está solo en etiquetar textos, sino en convertir grandes cantidades de opinión dispersa en información accionable.
Una empresa puede usarlo para detectar caídas de satisfacción, comparar productos, seguir campañas de marketing o descubrir qué aspectos generan más quejas. Un medio puede usarlo para estudiar la reacción del público. Un investigador puede usarlo para analizar percepción social en un conjunto amplio de mensajes.
20.7 Más allá de positivo y negativo
Aunque la formulación más conocida usa tres clases, muchos problemas reales requieren una representación más rica.
- Intensidad: no es lo mismo "bueno" que "excelente".
- Escala ordinal: por ejemplo, de 1 a 5 estrellas.
- Emociones específicas: alegría, enojo, sorpresa, tristeza.
- Sentimiento por aspecto: opinión sobre distintas partes del mismo objeto.
Esto muestra que el sentimiento no siempre se reduce a una sola etiqueta simple. A veces el desafío no es solo detectar orientación, sino también matiz.
20.8 Opinión global y opinión por aspecto
Un texto puede contener una valoración general del objeto completo o varias valoraciones sobre atributos diferentes. Esta distinción es muy importante.
Si alguien escribe "La pantalla es excelente, pero la batería dura poco", el sentimiento global es mixto. Hay una opinión positiva sobre la pantalla y una negativa sobre la batería.
Cuando el sistema intenta detectar sentimiento asociado a componentes concretos hablamos de análisis de sentimiento por aspecto. Este enfoque es más difícil, pero mucho más útil cuando interesa entender qué gusta o disgusta exactamente.
20.9 Pipeline clásico
En un enfoque tradicional con Machine Learning, el análisis de sentimiento suele seguir un pipeline parecido al siguiente:
- Recolección de opiniones o reseñas.
- Etiquetado de ejemplos con clases de sentimiento.
- Preprocesamiento del texto.
- Representación numérica con Bag of Words, TF-IDF o embeddings.
- Entrenamiento de un clasificador.
- Evaluación con datos no vistos.
- Uso del modelo sobre nuevos textos.
La lógica general es la misma que en clasificación de texto, pero aquí aparecen fenómenos lingüísticos que afectan mucho más el resultado.
20.10 Representaciones habituales
El análisis de sentimiento puede resolverse con distintas formas de representar el texto:
- Bag of Words: cuenta presencia o frecuencia de palabras.
- TF-IDF: pondera términos discriminativos.
- Embeddings: representan palabras o textos en vectores densos.
- Transformers: modelan contexto y relaciones más complejas.
La elección depende del nivel de complejidad buscado, la cantidad de datos disponible, el costo computacional y la dificultad del dominio.
20.11 El papel del preprocesamiento
El preprocesamiento puede ayudar, pero en análisis de sentimiento una limpieza excesiva puede destruir información valiosa.
Eliminar palabras vacías sin pensar, por ejemplo, puede borrar términos cruciales como "no", "nunca" o "jamás". Del mismo modo, quitar signos de exclamación o emoticonos puede hacer perder pistas importantes sobre intensidad o tono.
Por eso, en este problema conviene preguntarse siempre si la etapa de limpieza conserva las señales que realmente expresan opinión.
20.12 La negación cambia el sentido
Uno de los fenómenos más importantes en análisis de sentimiento es la negación. Una palabra positiva puede cambiar completamente de orientación si aparece negada.
- "Bueno" sugiere polaridad positiva.
- "No bueno" ya no significa lo mismo.
- "No me gustó" invierte una valoración potencialmente positiva.
Los modelos muy superficiales suelen cometer errores aquí, especialmente si solo cuentan palabras sin representar relaciones entre ellas.
20.13 Intensificadores y atenuadores
No solo importa la orientación de la opinión, sino también su intensidad. Expresiones como "muy bueno", "realmente excelente" o "bastante malo" agregan matices que no deberían ignorarse.
Los intensificadores refuerzan la valoración. Los atenuadores la suavizan. Un sistema robusto debería distinguir entre:
- "El servicio fue bueno".
- "El servicio fue muy bueno".
- "El servicio fue algo bueno".
En problemas reales, estas diferencias pueden afectar métricas de satisfacción, ranking de productos o alertas automáticas.
20.14 Ironía y sarcasmo
Uno de los obstáculos más difíciles es la ironía. Una frase puede contener palabras aparentemente positivas pero transmitir una evaluación negativa.
Por ejemplo, "Excelente, otra vez se colgó la aplicación" incluye la palabra "excelente", aunque el sentido real es claramente negativo.
Detectar ironía exige mucho contexto y, en muchos casos, conocimiento del mundo, tono discursivo o convenciones culturales. Por eso sigue siendo un desafío incluso para modelos modernos.
20.15 Subjetividad y ambigüedad
No siempre es fácil decidir si un texto expresa opinión o simplemente describe un hecho. Tampoco es fácil determinar si la opinión es positiva o negativa cuando el juicio es ambiguo o mixto.
Una reseña como "Cumple, pero esperaba más" puede ser interpretada como neutral por algunas personas y como levemente negativa por otras. Este tipo de casos muestra que las etiquetas no siempre son absolutas.
En consecuencia, los conjuntos de entrenamiento pueden contener desacuerdos entre anotadores humanos.
20.16 Datos etiquetados
Como en toda tarea supervisada, la calidad del análisis de sentimiento depende en gran medida de los datos. Para entrenar un modelo hacen falta textos etiquetados con la polaridad correcta o con la escala de opinión elegida.
El problema es que etiquetar sentimiento puede ser más subjetivo que etiquetar temas. Dos personas suelen coincidir en que una noticia trata sobre deportes, pero podrían discrepar sobre si un comentario es neutral o negativo.
Por eso, la definición de criterios de anotación es especialmente importante en este tipo de proyecto.
20.17 Desbalance de clases
En muchos dominios, las clases no aparecen con la misma frecuencia. Puede ocurrir, por ejemplo, que la mayoría de las reseñas sean positivas y que haya pocas negativas.
Si ignoramos ese desbalance, un modelo podría parecer bueno solo por predecir siempre la clase dominante. Por eso conviene mirar más que la simple exactitud global y prestar atención a métricas como precisión, recall y F1-score.
Este punto enlaza directamente con lo visto en el tema anterior sobre evaluación en clasificación de texto.
20.18 Comparación de enfoques
| Enfoque | Ventaja principal | Limitación principal |
|---|---|---|
| Lexicones y reglas | Simpleza e interpretabilidad. | Fragilidad frente a contexto real. |
| Machine Learning clásico | Buenos resultados con poco costo. | Representación superficial del contexto. |
| Embeddings y redes secuenciales | Mejor captación de relaciones semánticas. | Mayor complejidad y entrenamiento. |
| Transformers y LLM | Mejor manejo de contexto y matices. | Costo, sesgos y menor explicabilidad. |
20.19 Aplicaciones reales
El análisis de sentimiento se usa en muchos sectores:
- Monitoreo de reputación de marca.
- Análisis de reseñas de productos.
- Seguimiento de satisfacción de clientes.
- Estudio de reacción ante campañas o lanzamientos.
- Priorización de tickets con tono muy negativo.
- Investigación social basada en opinión pública.
En todos estos casos, el objetivo no suele ser etiquetar por etiquetar, sino detectar tendencias, riesgos y oportunidades.
20.20 Errores frecuentes al diseñar un sistema
Al construir un sistema de análisis de sentimiento, algunos errores muy comunes son:
- Creer que contar palabras positivas y negativas siempre alcanza.
- Eliminar negaciones durante el preprocesamiento.
- No diferenciar opinión global de opinión por aspecto.
- Usar un dataset de un dominio y esperar buen desempeño en otro muy distinto.
- Evaluar solo con exactitud sin mirar desbalance.
- Olvidar que la ironía y el sarcasmo generan fallos difíciles.
Estos puntos muestran que el problema es sencillo de formular, pero no necesariamente sencillo de resolver bien.
20.21 Cambio de dominio
Un modelo entrenado con reseñas de películas no necesariamente funcionará bien con comentarios sobre productos electrónicos, hoteles o política. Las palabras que expresan valoración y las formas discursivas cambian según el dominio.
Por ejemplo, la palabra "oscuro" podría tener una connotación positiva en una crítica cinematográfica y una negativa en la evaluación de una interfaz de usuario.
Esto obliga a tener cuidado con la generalización y, muchas veces, a adaptar el sistema al contexto específico de uso.
20.22 Ejemplo en Python: análisis de sentimiento con negaciones
Este ejemplo entrena un clasificador muy pequeño pero con un detalle importante: usa unigramas y bigramas para capturar expresiones como no recomiendo o muy bueno. Eso lo vuelve mucho más interesante que un simple conteo de palabras positivas y negativas.
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
reseñas = [
"la pelicula es excelente",
"no recomiendo esta pelicula",
"el servicio fue muy bueno",
"el servicio no fue bueno",
"la bateria dura mucho",
"la bateria no dura nada"
]
etiquetas = ["positivo", "negativo", "positivo", "negativo", "positivo", "negativo"]
modelo = Pipeline([
("tfidf", TfidfVectorizer(ngram_range=(1, 2))),
("clf", LogisticRegression(max_iter=1000))
])
modelo.fit(reseñas, etiquetas)
pruebas = [
"no fue una experiencia buena",
"muy buena pantalla pero bateria mala"
]
print(modelo.predict(pruebas))El ejemplo deja ver una idea central del tema: para sentimiento no alcanza con detectar palabras aisladas. Expresiones compuestas y negaciones cambian el sentido de forma decisiva.
20.23 Problema propuesto: laboratorio didáctico de análisis de sentimiento
Como actividad integradora podemos desarrollar una aplicación de escritorio con tkinter para explorar el análisis de sentimiento sobre reseñas de películas. La idea no es solo clasificar textos, sino construir una herramienta que permita recorrer todas las etapas del problema de forma visual y experimental.
Los objetivos principales de la aplicación pueden ser los siguientes:
- Descargar y cargar el corpus
movie_reviewsde NLTK como conjunto de datos de trabajo. - Mostrar un resumen del dataset y ejemplos aleatorios de reseñas positivas y negativas.
- Entrenar un pipeline de
TF-IDF + LogisticRegressionpara clasificación supervisada de sentimiento. - Evaluar el modelo con métricas como accuracy, precision, recall, F1-score y matriz de confusión.
- Permitir la clasificación de nuevas reseñas ingresadas por el usuario y mostrar probabilidades.
- Incorporar un análisis basado en reglas para estudiar negaciones, intensificadores y atenuadores.
- Agregar una vista de sentimiento por aspecto para distinguir opiniones sobre actuación, trama, final, música o imágenes.
- Comparar el enfoque de reglas con el enfoque de Machine Learning para discutir ventajas y limitaciones.
- Guardar y cargar el modelo entrenado para reutilizarlo sin repetir todo el proceso.
Este tipo de problema es especialmente valioso en un curso porque conecta teoría y práctica. Obliga a trabajar con recursos reales, entrenamiento, evaluación, explicabilidad e interacción con el usuario dentro de una misma aplicación.
import os
import re
import pickle
import random
import threading
import tkinter as tk
from tkinter import ttk, messagebox
from tkinter.scrolledtext import ScrolledText
import nltk
from nltk.corpus import movie_reviews
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
confusion_matrix,
classification_report,
)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
class AplicacionAnalisisSentimiento:
def __init__(self, root):
self.root = root
self.root.title("Sentiment Analysis - Didactic Laboratory")
self.root.geometry("1680x980")
self.carpeta_app = "sentimiento_app"
self.carpeta_datos = os.path.join(self.carpeta_app, "datos")
self.archivo_modelo = os.path.join(self.carpeta_datos, "modelo_sentimiento.pkl")
os.makedirs(self.carpeta_datos, exist_ok=True)
self.pipeline = None
self.vectorizador = None
self.clasificador = None
self.df_docs = []
self.X_train = None
self.X_test = None
self.y_train = None
self.y_test = None
self.entrenando = False
self.negaciones = {
"no", "not", "never", "n't", "hardly", "barely"
}
self.intensificadores = {
"very", "really", "extremely", "super", "absolutely",
"totally", "incredibly", "deeply", "highly"
}
self.atenuadores = {
"somewhat", "slightly", "a_bit", "kind_of", "rather",
"fairly", "moderately", "a_little"
}
self.lexico_positivo = {
"good", "great", "excellent", "amazing", "wonderful", "love", "loved",
"awesome", "fantastic", "perfect", "positive", "beautiful", "best",
"emotional", "powerful", "moving", "brilliant", "impressive", "strong",
"touching", "enjoyable", "smart", "well-made", "memorable"
}
self.lexico_negativo = {
"bad", "terrible", "awful", "hate", "hated", "boring", "worst", "poor",
"disappointing", "disappointed", "horrible", "negative", "ugly", "weak",
"slow", "confusing", "predictable", "messy", "flat", "dull", "annoying",
"ridiculous", "lifeless", "unconvincing"
}
self.aspectos = {
"acting": ["acting", "performances", "performance", "cast"],
"plot": ["plot", "story", "script", "narrative"],
"ending": ["ending", "finale", "conclusion"],
"soundtrack": ["soundtrack", "music", "score"],
"visuals": ["visuals", "cinematography", "images", "photography"],
"pacing": ["pacing", "rhythm", "tempo"],
"dialogue": ["dialogue", "lines", "writing"]
}
self.texto_demo_positivo = (
"The movie was really good, beautifully directed and emotionally powerful. "
"I loved the performances and the story was excellent."
)
self.texto_demo_negativo = (
"The movie was terrible. The plot was confusing, the acting felt weak, "
"and the ending was awful."
)
self.texto_demo_mixto = (
"The acting was excellent and the visuals were impressive, "
"but the plot felt slow and the ending was disappointing."
)
self.crear_interfaz()
# =========================================================
# INTERFAZ
# =========================================================
def crear_interfaz(self):
estilo = ttk.Style()
try:
estilo.theme_use("clam")
except:
pass
contenedor = ttk.Frame(self.root, padding=10)
contenedor.pack(fill="both", expand=True)
cabecera = ttk.Frame(contenedor)
cabecera.pack(fill="x", pady=(0, 10))
ttk.Label(
cabecera,
text="Sentiment Analysis - Didactic Application",
font=("Arial", 18, "bold")
).pack(anchor="w")
ttk.Label(
cabecera,
text=(
"Explore sentiment classification, negation, intensity, "
"aspects, and comparison between rules and Machine Learning."
),
font=("Arial", 10)
).pack(anchor="w", pady=(4, 0))
self.notebook = ttk.Notebook(contenedor)
self.notebook.pack(fill="both", expand=True)
self.crear_pestana_recursos()
self.crear_pestana_dataset()
self.crear_pestana_entrenamiento()
self.crear_pestana_evaluacion()
self.crear_pestana_inferencia()
self.crear_pestana_reglas()
self.crear_pestana_aspectos()
self.crear_pestana_comparacion()
# =========================================================
# UTILIDADES
# =========================================================
def insertar_texto(self, widget, texto):
widget.config(state="normal")
widget.delete("1.0", tk.END)
widget.insert(tk.END, texto)
widget.config(state="normal")
def obtener_texto(self, widget):
return widget.get("1.0", tk.END).strip()
def mostrar_error(self, titulo, mensaje):
messagebox.showerror(titulo, mensaje)
def mostrar_info(self, titulo, mensaje):
messagebox.showinfo(titulo, mensaje)
def tokenizar_simple(self, texto):
texto = texto.lower()
texto = texto.replace("a bit", "a_bit")
texto = texto.replace("kind of", "kind_of")
texto = texto.replace("a little", "a_little")
return re.findall(r"\b[\w']+\b", texto, flags=re.UNICODE)
def asegurar_dataset(self):
if not self.df_docs:
self.mostrar_error("Dataset not loaded", "First download and load the review corpus.")
return False
return True
def asegurar_modelo(self):
if self.pipeline is None:
self.mostrar_error("Model not trained", "First train or load a model.")
return False
return True
# =========================================================
# PESTAÑA 1 - RECURSOS
# =========================================================
def crear_pestana_recursos(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Resources")
izquierda = ttk.Frame(tab)
izquierda.pack(side="left", fill="both", expand=True, padx=(0, 8))
derecha = ttk.Frame(tab)
derecha.pack(side="left", fill="both", expand=True)
ttk.Label(
izquierda,
text="Introduction",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
texto = (
"This application presents sentiment analysis as a text classification problem.\n\n"
"Main ideas:\n"
"- A text can be positive, negative, or mixed.\n"
"- Sentiment depends on words, context, and structure.\n"
"- Negation can invert meaning.\n"
"- Intensifiers change the strength of an opinion.\n"
"- A review can express different opinions about different movie aspects.\n\n"
"The app combines two approaches:\n"
"1. Classical Machine Learning with TF-IDF + Logistic Regression.\n"
"2. A lexical/rule-based didactic approach to show negation and intensity."
)
self.txt_info_recursos = ScrolledText(izquierda, wrap="word", font=("Consolas", 11), height=28)
self.txt_info_recursos.pack(fill="both", expand=True)
self.txt_info_recursos.insert(tk.END, texto)
ttk.Label(
derecha,
text="NLTK Resources",
font=("Arial", 13, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Button(
derecha,
text="Download movie_reviews",
command=lambda: self.descargar_recurso_en_hilo("movie_reviews")
).pack(fill="x", pady=4)
ttk.Button(
derecha,
text="Download punkt",
command=lambda: self.descargar_recurso_en_hilo("punkt")
).pack(fill="x", pady=4)
ttk.Button(
derecha,
text="Download ALL required resources",
command=self.descargar_todos_en_hilo
).pack(fill="x", pady=4)
self.label_estado_recursos = ttk.Label(
derecha,
text="Status: resources not downloaded.",
foreground="blue"
)
self.label_estado_recursos.pack(anchor="w", pady=(15, 0))
self.txt_estado_recursos = ScrolledText(derecha, wrap="word", font=("Consolas", 11), height=18)
self.txt_estado_recursos.pack(fill="both", expand=True, pady=(10, 0))
def descargar_recurso_en_hilo(self, nombre):
def tarea():
try:
self.label_estado_recursos.config(text=f"Downloading {nombre}...", foreground="orange")
nltk.download(nombre, quiet=True)
self.label_estado_recursos.config(text=f"Resource {nombre} downloaded.", foreground="green")
self.insertar_texto(
self.txt_estado_recursos,
f"Resource downloaded successfully:\n\n{nombre}"
)
except Exception as e:
self.label_estado_recursos.config(text="Error downloading resource.", foreground="red")
self.mostrar_error("Error", str(e))
threading.Thread(target=tarea, daemon=True).start()
def descargar_todos_en_hilo(self):
def tarea():
try:
self.label_estado_recursos.config(text="Downloading resources...", foreground="orange")
for r in ["movie_reviews", "punkt"]:
nltk.download(r, quiet=True)
self.label_estado_recursos.config(text="Resources downloaded successfully.", foreground="green")
self.insertar_texto(
self.txt_estado_recursos,
"Main resources downloaded:\n\n- movie_reviews\n- punkt"
)
except Exception as e:
self.label_estado_recursos.config(text="Error downloading resources.", foreground="red")
self.mostrar_error("Error", str(e))
threading.Thread(target=tarea, daemon=True).start()
# =========================================================
# PESTAÑA 2 - DATASET
# =========================================================
def crear_pestana_dataset(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Dataset")
ttk.Label(
tab,
text="Movie Review Dataset",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Load movie_reviews corpus", command=self.cargar_dataset_movie_reviews).pack(side="left", padx=4)
ttk.Button(controles, text="Show summary", command=self.mostrar_resumen_dataset).pack(side="left", padx=4)
ttk.Button(controles, text="Show random examples", command=self.mostrar_ejemplos_dataset).pack(side="left", padx=4)
self.label_estado_dataset = ttk.Label(
controles,
text="Status: dataset not loaded.",
foreground="blue"
)
self.label_estado_dataset.pack(side="left", padx=12)
self.txt_dataset = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=30)
self.txt_dataset.pack(fill="both", expand=True)
def cargar_dataset_movie_reviews(self):
try:
docs = []
for categoria in movie_reviews.categories():
for fileid in movie_reviews.fileids(categoria):
texto = " ".join(movie_reviews.words(fileid))
docs.append((texto, categoria))
random.shuffle(docs)
self.df_docs = docs
self.label_estado_dataset.config(
text=f"Dataset loaded. Documents: {len(self.df_docs)}",
foreground="green"
)
self.mostrar_resumen_dataset()
except LookupError:
self.mostrar_error(
"Missing resource",
"movie_reviews is missing. Go to the Resources tab and download it."
)
except Exception as e:
self.mostrar_error("Error", str(e))
def mostrar_resumen_dataset(self):
if not self.asegurar_dataset():
return
total = len(self.df_docs)
positivos = sum(1 for _, y in self.df_docs if y == "pos")
negativos = sum(1 for _, y in self.df_docs if y == "neg")
longitudes = [len(texto.split()) for texto, _ in self.df_docs]
salida = "DATASET SUMMARY\n\n"
salida += f"Total number of reviews: {total}\n"
salida += f"Positive: {positivos}\n"
salida += f"Negative: {negativos}\n\n"
salida += f"Average words per review: {sum(longitudes) / len(longitudes):.2f}\n"
salida += f"Minimum words: {min(longitudes)}\n"
salida += f"Maximum words: {max(longitudes)}\n\n"
salida += "This corpus is useful for training a binary sentiment classifier."
self.insertar_texto(self.txt_dataset, salida)
def mostrar_ejemplos_dataset(self):
if not self.asegurar_dataset():
return
positivos = [t for t, y in self.df_docs if y == "pos"]
negativos = [t for t, y in self.df_docs if y == "neg"]
salida = "RANDOM EXAMPLES FROM THE DATASET\n\n"
salida += "POSITIVE REVIEW\n"
salida += "-" * 70 + "\n"
salida += random.choice(positivos)[:1500] + "\n\n"
salida += "NEGATIVE REVIEW\n"
salida += "-" * 70 + "\n"
salida += random.choice(negativos)[:1500] + "\n"
self.insertar_texto(self.txt_dataset, salida)
# =========================================================
# PESTAÑA 3 - ENTRENAMIENTO
# =========================================================
def crear_pestana_entrenamiento(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Training")
ttk.Label(
tab,
text="Training Pipeline",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Label(controles, text="Test size:").pack(side="left", padx=(0, 5))
self.entry_test_size = ttk.Entry(controles, width=8)
self.entry_test_size.pack(side="left")
self.entry_test_size.insert(0, "0.25")
ttk.Label(controles, text="TF-IDF max_features:").pack(side="left", padx=(15, 5))
self.entry_max_features = ttk.Entry(controles, width=10)
self.entry_max_features.pack(side="left")
self.entry_max_features.insert(0, "12000")
self.var_bigramas = tk.BooleanVar(value=True)
ttk.Checkbutton(
controles,
text="Use bigrams",
variable=self.var_bigramas
).pack(side="left", padx=10)
ttk.Button(controles, text="Train model", command=self.entrenar_modelo_en_hilo).pack(side="left", padx=8)
self.label_estado_entrenamiento = ttk.Label(
controles,
text="Status: model not trained.",
foreground="blue"
)
self.label_estado_entrenamiento.pack(side="left", padx=10)
self.txt_entrenamiento = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=30)
self.txt_entrenamiento.pack(fill="both", expand=True)
def entrenar_modelo_en_hilo(self):
if not self.asegurar_dataset():
return
if self.entrenando:
return
def tarea():
try:
self.entrenando = True
self.label_estado_entrenamiento.config(text="Training model...", foreground="orange")
test_size = float(self.entry_test_size.get())
max_features = int(self.entry_max_features.get())
ngram = (1, 2) if self.var_bigramas.get() else (1, 1)
X = [texto for texto, y in self.df_docs]
y = [1 if y == "pos" else 0 for _, y in self.df_docs]
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
X, y,
test_size=test_size,
random_state=42,
stratify=y
)
self.pipeline = Pipeline([
("tfidf", TfidfVectorizer(
lowercase=True,
strip_accents="unicode",
max_features=max_features,
ngram_range=ngram,
min_df=2
)),
("clf", LogisticRegression(
max_iter=3000,
solver="liblinear",
class_weight="balanced"
))
])
self.pipeline.fit(self.X_train, self.y_train)
self.vectorizador = self.pipeline.named_steps["tfidf"]
self.clasificador = self.pipeline.named_steps["clf"]
salida = "TRAINING COMPLETED\n\n"
salida += f"Total reviews: {len(X)}\n"
salida += f"Training set: {len(self.X_train)}\n"
salida += f"Test set: {len(self.X_test)}\n\n"
salida += "Pipeline used:\n"
salida += "- TF-IDF\n"
salida += f"- max_features = {max_features}\n"
salida += f"- ngram_range = {ngram}\n"
salida += "- LogisticRegression\n"
salida += "- class_weight = balanced\n"
self.insertar_texto(self.txt_entrenamiento, salida)
self.label_estado_entrenamiento.config(text="Model trained successfully.", foreground="green")
except Exception as e:
self.label_estado_entrenamiento.config(text="Training error.", foreground="red")
self.mostrar_error("Error", str(e))
finally:
self.entrenando = False
threading.Thread(target=tarea, daemon=True).start()
# =========================================================
# PESTAÑA 4 - EVALUACIÓN
# =========================================================
def crear_pestana_evaluacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Evaluation")
ttk.Label(
tab,
text="Evaluation and Interpretation",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Evaluate model", command=self.evaluar_modelo).pack(side="left", padx=4)
ttk.Button(controles, text="Show errors", command=self.mostrar_errores).pack(side="left", padx=4)
ttk.Button(controles, text="Most positive words", command=self.mostrar_palabras_positivas).pack(side="left", padx=4)
ttk.Button(controles, text="Most negative words", command=self.mostrar_palabras_negativas).pack(side="left", padx=4)
self.txt_evaluacion = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=30)
self.txt_evaluacion.pack(fill="both", expand=True)
def evaluar_modelo(self):
if not self.asegurar_modelo():
return
try:
y_pred = self.pipeline.predict(self.X_test)
acc = accuracy_score(self.y_test, y_pred)
prec = precision_score(self.y_test, y_pred, zero_division=0)
rec = recall_score(self.y_test, y_pred, zero_division=0)
f1 = f1_score(self.y_test, y_pred, zero_division=0)
cm = confusion_matrix(self.y_test, y_pred)
salida = "SENTIMENT CLASSIFIER EVALUATION\n\n"
salida += f"Accuracy : {acc:.4f}\n"
salida += f"Precision: {prec:.4f}\n"
salida += f"Recall : {rec:.4f}\n"
salida += f"F1-score : {f1:.4f}\n\n"
salida += "Confusion Matrix\n"
salida += " Pred neg Pred pos\n"
salida += f"Real neg {cm[0,0]:>10} {cm[0,1]:>12}\n"
salida += f"Real pos {cm[1,0]:>10} {cm[1,1]:>12}\n\n"
salida += classification_report(
self.y_test,
y_pred,
target_names=["negative", "positive"],
zero_division=0
)
self.insertar_texto(self.txt_evaluacion, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
def mostrar_errores(self):
if not self.asegurar_modelo():
return
try:
y_pred = self.pipeline.predict(self.X_test)
probs = self.pipeline.predict_proba(self.X_test)
errores = []
for texto, real, pred, prob in zip(self.X_test, self.y_test, y_pred, probs):
if real != pred:
errores.append((texto, real, pred, prob[1]))
salida = "MODEL ERRORS ON THE TEST SET\n\n"
salida += f"Number of errors: {len(errores)}\n\n"
for i, (texto, real, pred, prob_pos) in enumerate(errores[:12], start=1):
salida += f"Error {i}\n"
salida += f"Real: {'positive' if real == 1 else 'negative'}\n"
salida += f"Pred: {'positive' if pred == 1 else 'negative'}\n"
salida += f"Positive probability: {prob_pos:.4f}\n"
salida += f"Text: {texto[:700]}...\n"
salida += "-" * 80 + "\n"
self.insertar_texto(self.txt_evaluacion, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
def mostrar_palabras_positivas(self):
self.mostrar_palabras_por_peso(objetivo="positivo")
def mostrar_palabras_negativas(self):
self.mostrar_palabras_por_peso(objetivo="negativo")
def mostrar_palabras_por_peso(self, objetivo="positivo"):
if not self.asegurar_modelo():
return
try:
vocab = self.vectorizador.get_feature_names_out()
coef = self.clasificador.coef_[0]
if objetivo == "positivo":
indices = coef.argsort()[-40:][::-1]
titulo = "WORDS WITH THE STRONGEST POSITIVE WEIGHT"
else:
indices = coef.argsort()[:40]
titulo = "WORDS WITH THE STRONGEST NEGATIVE WEIGHT"
salida = titulo + "\n\n"
salida += f"{'TERM':<30}{'WEIGHT':>12}\n"
salida += "-" * 45 + "\n"
for idx in indices:
salida += f"{vocab[idx]:<30}{coef[idx]:>12.6f}\n"
self.insertar_texto(self.txt_evaluacion, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
# =========================================================
# PESTAÑA 5 - INFERENCIA
# =========================================================
def crear_pestana_inferencia(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Classify Review")
ttk.Label(
tab,
text="Classify a New Movie Review",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Write a movie review here:").pack(anchor="w")
self.txt_inferencia_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_inferencia_entrada.pack(fill="x", pady=(0, 8))
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_mixto)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Classify with ML", command=self.clasificar_texto_ml).pack(side="left", padx=4)
ttk.Button(controles, text="Positive example", command=self.cargar_demo_positivo).pack(side="left", padx=4)
ttk.Button(controles, text="Negative example", command=self.cargar_demo_negativo).pack(side="left", padx=4)
ttk.Button(controles, text="Mixed example", command=self.cargar_demo_mixto).pack(side="left", padx=4)
ttk.Button(controles, text="Clear", command=lambda: self.txt_inferencia_entrada.delete("1.0", tk.END)).pack(side="left", padx=4)
self.txt_inferencia_salida = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=25)
self.txt_inferencia_salida.pack(fill="both", expand=True)
def cargar_demo_positivo(self):
self.txt_inferencia_entrada.delete("1.0", tk.END)
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_positivo)
def cargar_demo_negativo(self):
self.txt_inferencia_entrada.delete("1.0", tk.END)
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_negativo)
def cargar_demo_mixto(self):
self.txt_inferencia_entrada.delete("1.0", tk.END)
self.txt_inferencia_entrada.insert(tk.END, self.texto_demo_mixto)
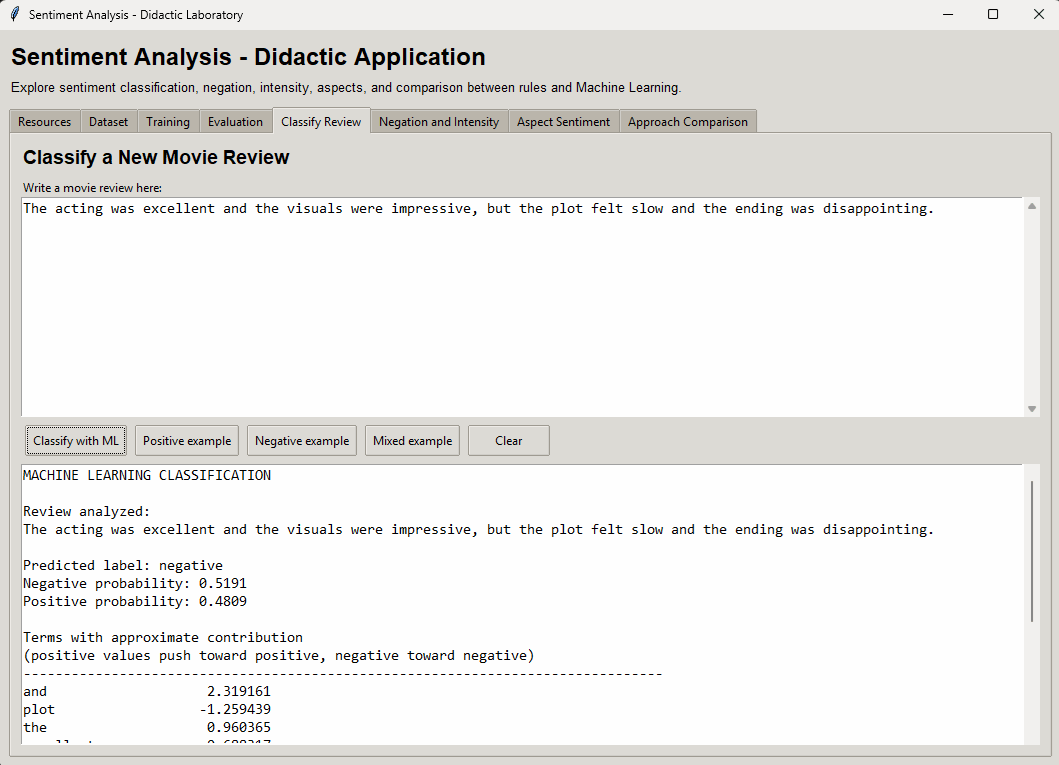
def clasificar_texto_ml(self):
if not self.asegurar_modelo():
return
texto = self.obtener_texto(self.txt_inferencia_entrada)
if not texto:
self.mostrar_error("Error", "You must write a review.")
return
try:
pred = self.pipeline.predict([texto])[0]
probs = self.pipeline.predict_proba([texto])[0]
etiqueta = "positive" if pred == 1 else "negative"
salida = "MACHINE LEARNING CLASSIFICATION\n\n"
salida += f"Review analyzed:\n{texto}\n\n"
salida += f"Predicted label: {etiqueta}\n"
salida += f"Negative probability: {probs[0]:.4f}\n"
salida += f"Positive probability: {probs[1]:.4f}\n\n"
tokens = self.tokenizar_simple(texto)
contribuciones = []
vocab = self.vectorizador.vocabulary_
coef = self.clasificador.coef_[0]
for token in tokens:
if token in vocab:
idx = vocab[token]
contribuciones.append((token, coef[idx]))
if contribuciones:
salida += "Terms with approximate contribution\n"
salida += "(positive values push toward positive, negative toward negative)\n"
salida += "-" * 80 + "\n"
vistos = set()
for palabra, peso in sorted(contribuciones, key=lambda x: abs(x[1]), reverse=True):
if palabra not in vistos:
salida += f"{palabra:<20} {peso:>10.6f}\n"
vistos.add(palabra)
if len(vistos) >= 20:
break
self.insertar_texto(self.txt_inferencia_salida, salida)
except Exception as e:
self.mostrar_error("Error", str(e))
# =========================================================
# PESTAÑA 6 - REGLAS
# =========================================================
def crear_pestana_reglas(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Negation and Intensity")
ttk.Label(
tab,
text="Rule-based Didactic Analysis",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Input review:").pack(anchor="w")
self.txt_reglas_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_reglas_entrada.pack(fill="x", pady=(0, 8))
self.txt_reglas_entrada.insert(
tk.END,
"The movie is not good. The acting is very strong, but the ending is slightly weak. Great, it bored me again."
)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Analyze with rules", command=self.analizar_reglas).pack(side="left", padx=4)
ttk.Button(controles, text="Negation example", command=self.cargar_ejemplo_negacion).pack(side="left", padx=4)
ttk.Button(controles, text="Intensity example", command=self.cargar_ejemplo_intensidad).pack(side="left", padx=4)
ttk.Button(controles, text="Irony example", command=self.cargar_ejemplo_ironia).pack(side="left", padx=4)
self.txt_reglas_salida = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=25)
self.txt_reglas_salida.pack(fill="both", expand=True)
def cargar_ejemplo_negacion(self):
self.txt_reglas_entrada.delete("1.0", tk.END)
self.txt_reglas_entrada.insert(
tk.END,
"The movie is not good. I never liked the ending. It is not excellent at all."
)
def cargar_ejemplo_intensidad(self):
self.txt_reglas_entrada.delete("1.0", tk.END)
self.txt_reglas_entrada.insert(
tk.END,
"The acting was very good, really excellent, but the plot was slightly weak."
)
def cargar_ejemplo_ironia(self):
self.txt_reglas_entrada.delete("1.0", tk.END)
self.txt_reglas_entrada.insert(
tk.END,
"Excellent, another masterpiece that put me to sleep. Great, the ending ruined everything again."
)
def puntaje_lexico(self, texto):
tokens = self.tokenizar_simple(texto)
detalle = []
score = 0.0
for i, token in enumerate(tokens):
base = 0.0
if token in self.lexico_positivo:
base = 1.0
elif token in self.lexico_negativo:
base = -1.0
if base != 0:
factor = 1.0
ventana_prev = tokens[max(0, i - 3):i]
if any(t in self.negaciones for t in ventana_prev):
base *= -1
detalle.append(f"Inversion caused by negation near '{token}'")
if any(t in self.intensificadores for t in ventana_prev):
factor *= 1.8
detalle.append(f"Intensification near '{token}'")
if any(t in self.atenuadores for t in ventana_prev):
factor *= 0.6
detalle.append(f"Attenuation near '{token}'")
valor = base * factor
score += valor
return score, detalle, tokens
def analizar_reglas(self):
texto = self.obtener_texto(self.txt_reglas_entrada)
if not texto:
self.mostrar_error("Error", "Enter a review.")
return
score, detalle, tokens = self.puntaje_lexico(texto)
if score > 0.8:
etiqueta = "positive"
elif score < -0.8:
etiqueta = "negative"
else:
etiqueta = "neutral or mixed"
salida = "RULE-BASED DIDACTIC ANALYSIS\n\n"
salida += f"Review analyzed:\n{texto}\n\n"
salida += f"Approximate lexical score: {score:.2f}\n"
salida += f"Approximate label: {etiqueta}\n\n"
salida += "Detected tokens:\n"
salida += str(tokens) + "\n\n"
salida += "Detected phenomena:\n"
salida += "-" * 70 + "\n"
if detalle:
for item in detalle:
salida += f"- {item}\n"
else:
salida += "- No special phenomena were detected in the defined vocabulary.\n"
salida += "\nDidactic note:\n"
salida += (
"This rule-based analysis is simple and interpretable, but fragile when facing "
"real context, irony, and vocabulary outside the lexicon."
)
self.insertar_texto(self.txt_reglas_salida, salida)
# =========================================================
# PESTAÑA 7 - ASPECTOS
# =========================================================
def crear_pestana_aspectos(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Aspect Sentiment")
ttk.Label(
tab,
text="Sentiment by Movie Aspect",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Input review:").pack(anchor="w")
self.txt_aspectos_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_aspectos_entrada.pack(fill="x", pady=(0, 8))
self.txt_aspectos_entrada.insert(tk.END, self.texto_demo_mixto)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Analyze aspects", command=self.analizar_aspectos).pack(side="left", padx=4)
ttk.Button(controles, text="Mixed example", command=lambda: self._set_text(self.txt_aspectos_entrada, self.texto_demo_mixto)).pack(side="left", padx=4)
ttk.Button(controles, text="Technical review example", command=self.cargar_ejemplo_tecnico).pack(side="left", padx=4)
self.txt_aspectos_salida = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=25)
self.txt_aspectos_salida.pack(fill="both", expand=True)
def _set_text(self, widget, texto):
widget.delete("1.0", tk.END)
widget.insert(tk.END, texto)
def cargar_ejemplo_tecnico(self):
self._set_text(
self.txt_aspectos_entrada,
"The acting is very good and the visuals are excellent, but the plot is terrible and the ending does not work at all."
)
def analizar_aspectos(self):
texto = self.obtener_texto(self.txt_aspectos_entrada)
if not texto:
self.mostrar_error("Error", "Enter a review.")
return
tokens = self.tokenizar_simple(texto)
salida = "ASPECT-BASED SENTIMENT ANALYSIS\n\n"
salida += f"Review:\n{texto}\n\n"
encontrados = False
for aspecto, alias in self.aspectos.items():
posiciones = [i for i, tok in enumerate(tokens) if tok in alias]
if not posiciones:
continue
encontrados = True
score_aspecto = 0.0
evidencias = []
for pos in posiciones:
inicio = max(0, pos - 4)
fin = min(len(tokens), pos + 5)
ventana = tokens[inicio:fin]
ventana_texto = " ".join(ventana)
puntaje, detalle, _ = self.puntaje_lexico(ventana_texto)
score_aspecto += puntaje
evidencias.append((ventana_texto, puntaje, detalle))
if score_aspecto > 0.8:
etiqueta = "positive"
elif score_aspecto < -0.8:
etiqueta = "negative"
else:
etiqueta = "mixed or neutral"
salida += f"ASPECT: {aspecto}\n"
salida += f"Accumulated score: {score_aspecto:.2f}\n"
salida += f"Label: {etiqueta}\n"
salida += "Local evidence:\n"
for ventana_texto, puntaje, detalle in evidencias:
salida += f" - Window: {ventana_texto}\n"
salida += f" Score: {puntaje:.2f}\n"
if detalle:
for d in detalle:
salida += f" * {d}\n"
salida += "-" * 70 + "\n"
if not encontrados:
salida += "No aspects from the defined vocabulary were detected.\n"
salida += (
"\nKey idea:\n"
"A review can be globally mixed even when some aspects are clearly positive "
"and others clearly negative."
)
self.insertar_texto(self.txt_aspectos_salida, salida)
# =========================================================
# PESTAÑA 8 - COMPARACIÓN
# =========================================================
def crear_pestana_comparacion(self):
tab = ttk.Frame(self.notebook, padding=10)
self.notebook.add(tab, text="Approach Comparison")
ttk.Label(
tab,
text="Compare Rules vs Machine Learning",
font=("Arial", 14, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(tab, text="Review to compare:").pack(anchor="w")
self.txt_comparacion_entrada = ScrolledText(tab, wrap="word", height=12, font=("Consolas", 11))
self.txt_comparacion_entrada.pack(fill="x", pady=(0, 8))
self.txt_comparacion_entrada.insert(
tk.END,
"The acting is very good, but the plot is not good and the ending is terrible."
)
controles = ttk.Frame(tab)
controles.pack(fill="x", pady=(0, 8))
ttk.Button(controles, text="Compare ML vs Rules", command=self.comparar_enfoques).pack(side="left", padx=4)
ttk.Button(controles, text="Save model", command=self.guardar_modelo).pack(side="left", padx=4)
ttk.Button(controles, text="Load model", command=self.cargar_modelo).pack(side="left", padx=4)
self.txt_comparacion_salida = ScrolledText(tab, wrap="word", font=("Consolas", 11), height=25)
self.txt_comparacion_salida.pack(fill="both", expand=True)
def comparar_enfoques(self):
texto = self.obtener_texto(self.txt_comparacion_entrada)
if not texto:
self.mostrar_error("Error", "Enter a review.")
return
salida = "APPROACH COMPARISON\n\n"
salida += f"Review:\n{texto}\n\n"
score, detalle, _ = self.puntaje_lexico(texto)
if score > 0.8:
etiqueta_reglas = "positive"
elif score < -0.8:
etiqueta_reglas = "negative"
else:
etiqueta_reglas = "neutral or mixed"
salida += "1. LEXICON / RULE-BASED APPROACH\n"
salida += f"- Score: {score:.2f}\n"
salida += f"- Label: {etiqueta_reglas}\n"
if detalle:
salida += "- Detected phenomena:\n"
for d in detalle[:12]:
salida += f" * {d}\n"
else:
salida += "- No special phenomena detected.\n"
salida += "\n2. CLASSICAL MACHINE LEARNING\n"
if self.pipeline is None:
salida += "- Model not trained yet.\n"
else:
pred = self.pipeline.predict([texto])[0]
probs = self.pipeline.predict_proba([texto])[0]
salida += f"- Label: {'positive' if pred == 1 else 'negative'}\n"
salida += f"- Negative probability: {probs[0]:.4f}\n"
salida += f"- Positive probability: {probs[1]:.4f}\n"
salida += (
"\nDidactic conclusion:\n"
"Rules are interpretable and clearly show linguistic phenomena. "
"Machine Learning usually generalizes better inside the training domain, "
"but it can still fail when the domain changes or irony appears."
)
self.insertar_texto(self.txt_comparacion_salida, salida)
# =========================================================
# GUARDAR / CARGAR MODELO
# =========================================================
def guardar_modelo(self):
if not self.asegurar_modelo():
return
try:
with open(self.archivo_modelo, "wb") as f:
pickle.dump({"pipeline": self.pipeline}, f)
self.mostrar_info("Model saved", f"Model saved in:\n{self.archivo_modelo}")
except Exception as e:
self.mostrar_error("Error", str(e))
def cargar_modelo(self):
try:
if not os.path.exists(self.archivo_modelo):
self.mostrar_error("File not found", "There is no saved model yet.")
return
with open(self.archivo_modelo, "rb") as f:
datos = pickle.load(f)
self.pipeline = datos["pipeline"]
self.vectorizador = self.pipeline.named_steps["tfidf"]
self.clasificador = self.pipeline.named_steps["clf"]
self.mostrar_info("Model loaded", "The model was loaded successfully.")
except Exception as e:
self.mostrar_error("Error", str(e))
# =========================================================
# PROGRAMA PRINCIPAL
# =========================================================
if __name__ == "__main__":
root = tk.Tk()
app = AplicacionAnalisisSentimiento(root)
root.mainloop()20.24 Qué debes recordar de este tema
- El análisis de sentimiento busca identificar la orientación opinativa de un texto.
- Puede modelarse como un problema de clasificación de texto.
- La polaridad básica suele ser positiva, negativa o neutral.
- La negación, la intensidad, la ironía y el contexto complican mucho la tarea.
- La versión por aspecto permite un análisis más fino que la polaridad global.
- La calidad del sistema depende de datos, representación, evaluación y dominio.
20.25 Conclusión
El análisis de sentimiento es uno de los ejemplos más claros de cómo una tarea aparentemente intuitiva puede volverse compleja cuando intentamos automatizarla. Detrás de una simple etiqueta de polaridad aparecen problemas de contexto, subjetividad, composición lingüística e interpretación pragmática.
Al mismo tiempo, sigue siendo una aplicación de enorme valor práctico porque permite resumir la percepción de miles o millones de textos en forma automática.
En el próximo tema comenzaremos a estudiar los modelos de lenguaje básicos, una idea fundamental para entender cómo los sistemas de NLP aprenden regularidades del texto y predicen secuencias lingüísticas.