11. Operaciones sobre píxeles y matrices
11.1 Introducción
En visión por computadora, trabajar con imágenes significa trabajar con matrices. Cada operación sobre una imagen, por simple o compleja que parezca, termina siendo una operación sobre sus píxeles o sobre grupos de píxeles organizados numéricamente.
Por eso este tema es especialmente importante: nos obliga a pensar las imágenes no como fotografías, sino como estructuras matemáticas sobre las que podemos sumar, restar, multiplicar, comparar, recortar, combinar y transformar datos.
Comprender bien estas operaciones permite ganar una intuición muy valiosa. Más adelante, cuando estudiemos filtros, convoluciones, CNN o segmentación, veremos que muchas ideas se apoyan directamente sobre este mismo principio.
11.2 La imagen como matriz numérica
Recordemos la idea fundamental: una imagen en escala de grises puede representarse como una matriz bidimensional, y una imagen en color como una estructura tridimensional donde la tercera dimensión corresponde a los canales.
Por ejemplo:
(alto, ancho)para una imagen en grises.(alto, ancho, 3)para una imagen en color.
Esto significa que una imagen puede manipularse igual que cualquier otro arreglo numérico de NumPy. Esa compatibilidad es una de las razones por las que Python resulta tan cómodo para visión por computadora.
11.3 Acceso a un píxel individual
La operación más elemental consiste en leer el valor de un píxel concreto. Si la imagen está cargada como arreglo de NumPy:
valor = imagen[120, 250]
print(valor)Si la imagen es en grises, obtendremos un único número. Si es en color, obtendremos un vector de varios componentes.
Este acceso puntual es útil para inspección y comprensión, aunque en procesamiento real casi siempre trabajaremos sobre regiones completas.
11.4 Modificación de un píxel
También es posible asignar un nuevo valor a un píxel:
imagen[120, 250] = 255Si la imagen está en grises, eso convierte ese píxel en blanco. En una imagen en color, podríamos asignar un vector:
imagen[120, 250] = [0, 255, 0]En OpenCV, recordar que eso se interpreta en BGR si la imagen fue cargada con cv2.imread.
11.5 ¿Por qué no conviene recorrer píxel por píxel?
Aunque acceder a píxeles individuales es conceptualmente útil, en la práctica no conviene construir la mayoría de los algoritmos recorriendo píxel por píxel con bucles de Python. Esto suele ser lento e ineficiente.
La alternativa recomendada es usar operaciones vectorizadas de NumPy u operaciones optimizadas de OpenCV. Estas herramientas trabajan sobre bloques completos de datos y aprovechan implementaciones mucho más rápidas.
11.6 Slicing: trabajar con regiones
Una operación mucho más poderosa que el acceso puntual es el slicing, es decir, seleccionar rangos de filas y columnas. Por ejemplo:
region = imagen[50:200, 100:300]Esto devuelve una submatriz de la imagen. Las regiones de interés son fundamentales en procesamiento visual porque muchas veces solo una parte de la imagen nos interesa realmente.
11.7 Modificar una región completa
Al igual que con un solo píxel, también podemos modificar una región entera de una vez:
imagen[50:200, 100:300] = 0En una imagen en grises, esto convierte esa región en negro. Si la imagen es color, todos los canales de esa región se pondrán en cero.
Este tipo de operación muestra el poder de trabajar matricialmente: con una sola línea podemos alterar miles de píxeles.
11.8 Vistas y copias
Un detalle importante es que muchas operaciones de slicing en NumPy devuelven una vista y no una copia independiente. Eso significa que si modificamos la región recortada, podría modificarse también la imagen original.
Si queremos evitar ese comportamiento, debemos crear una copia explícita:
region = imagen[50:200, 100:300].copy()Entender esta diferencia es clave para no introducir errores sutiles durante el procesamiento.
11.9 Operaciones aritméticas básicas
Como las imágenes son matrices numéricas, podemos aplicar operaciones aritméticas elementales sobre ellas. Por ejemplo:
- Sumar un valor para aumentar brillo.
- Restar un valor para oscurecer.
- Multiplicar por un factor para cambiar contraste.
- Sumar o restar dos imágenes.
Ejemplo de suma:
import numpy as np
resultado = np.clip(imagen + 20, 0, 255).astype(np.uint8)La idea es muy simple: alteramos todos los valores a la vez.
11.10 Suma de imágenes
También es posible sumar dos imágenes del mismo tamaño. Esto puede utilizarse para combinaciones, composiciones o análisis.
suma = cv2.add(imagen1, imagen2)Usar cv2.add en lugar del operador + puede ser conveniente porque OpenCV controla la saturación dentro del rango válido.
11.11 Resta de imágenes
La resta también puede ser útil. Por ejemplo, para resaltar diferencias entre dos capturas:
diferencia = cv2.subtract(imagen1, imagen2)Esto aparece en tareas como detección de cambios, comparación entre frames y análisis de movimiento simple.
11.12 Multiplicación por escalar
Multiplicar una imagen por un escalar modifica la intensidad general. Por ejemplo:
resultado = np.clip(imagen * 1.5, 0, 255).astype(np.uint8)Esto suele aumentar el contraste o la intensidad, según el contexto. Nuevamente, conviene controlar rangos y tipos de dato.
11.13 Tipos de dato y overflow
Una de las fuentes más comunes de error al trabajar con operaciones matriciales es olvidar el tipo de dato. Si una imagen está en uint8, sus valores van de 0 a 255. Ciertas operaciones pueden producir overflow o comportamientos inesperados si no se controla esto.
Por eso conviene:
- Convertir a flotante cuando sea necesario.
- Usar
np.clippara limitar el rango. - Volver a
uint8al final si corresponde.
temp = imagen.astype(np.float32)
temp = temp * 1.3 + 10
resultado = np.clip(temp, 0, 255).astype(np.uint8)11.14 Comparaciones matriciales
No solo podemos sumar o multiplicar. También podemos comparar valores píxel a píxel para construir máscaras lógicas. Por ejemplo:
mascara = gris > 128Esto genera una matriz booleana donde cada posición indica si el píxel cumple la condición. Las comparaciones matriciales son la base de muchas operaciones de segmentación simple.
11.15 Máscaras
Una máscara es una estructura que indica qué píxeles deben seleccionarse, modificarse o conservarse. Puede ser booleana o binaria.
Por ejemplo, si queremos dejar en negro todos los píxeles con intensidad baja:
resultado = imagen.copy()
resultado[gris < 100] = 0Este tipo de técnica es muy poderosa porque permite actuar solo sobre partes de la imagen que cumplen una condición.
11.16 Operaciones lógicas
OpenCV también ofrece operaciones lógicas útiles cuando trabajamos con imágenes binarias o máscaras:
bitwise_andbitwise_orbitwise_xorbitwise_not
Ejemplo:
resultado = cv2.bitwise_and(imagen, imagen, mask=mascara_binaria)Estas operaciones son fundamentales cuando queremos combinar regiones, aplicar recortes con forma o construir pipelines de segmentación.
11.17 Umbralización como operación matricial
Aunque ya vimos la umbralización en el tema anterior, aquí conviene reinterpretarla como operación sobre matrices. Lo que hace una umbralización es decidir, para cada valor de la matriz, qué salida asignar.
En términos conceptuales:
- Si el valor supera cierto umbral, asignamos un valor alto.
- Si no, asignamos un valor bajo.
Esto refuerza la idea de que muchas técnicas de procesamiento pueden entenderse como reglas matemáticas aplicadas píxel a píxel o región a región.
11.18 Operaciones canal por canal
En imágenes color, las operaciones matriciales pueden aplicarse sobre todos los canales o sobre uno solo. Por ejemplo, podemos aumentar el canal rojo, atenuar el azul o trabajar solo sobre la luminancia si cambiamos de espacio de color.
Separar canales y operar individualmente puede ser útil cuando un objeto se destaca especialmente en una componente concreta.
b, g, r = cv2.split(imagen)
r = np.clip(r + 30, 0, 255).astype(np.uint8)
resultado = cv2.merge([b, g, r])11.19 Indexación booleana
Una herramienta muy potente de NumPy es la indexación booleana. Permite seleccionar directamente todos los píxeles que cumplan una condición.
Por ejemplo:
imagen[gris > 200] = [0, 0, 255]Este código cambia a rojo todos los píxeles cuya intensidad en la imagen de grises supere 200. Es una forma compacta y eficiente de aplicar reglas sobre grandes cantidades de datos.
11.20 Apilado y reorganización de matrices
En algunos casos conviene reorganizar la estructura de los datos. Por ejemplo, podemos apilar imágenes o canales para formar una nueva composición visual. Con NumPy esto puede hacerse usando funciones como:
np.hstacknp.vstacknp.stacknp.concatenate
Esto es útil para comparar resultados lado a lado o construir nuevas representaciones.
11.21 Normalización de matrices
En muchos pipelines conviene escalar los valores a un rango más manejable, por ejemplo entre 0 y 1. Esto se conoce como normalización.
normalizada = imagen.astype(np.float32) / 255.0Esta operación es especialmente frecuente antes de alimentar imágenes a modelos de Deep Learning.
11.22 Estadísticas sobre la imagen
Como la imagen es una matriz, podemos calcular estadísticas sobre ella:
- Promedio.
- Máximo.
- Mínimo.
- Desviación estándar.
print(imagen.mean())
print(imagen.max())
print(imagen.min())Estas medidas ayudan a entender la distribución de intensidades y sirven como base para análisis posteriores, como histogramas y normalizaciones.
11.23 Operaciones matriciales y eficiencia
Uno de los beneficios más importantes de pensar en imágenes como matrices es la eficiencia computacional. Operar con vectores y matrices completas permite aprovechar implementaciones internas optimizadas, en lugar de depender de bucles lentos de Python.
En la práctica, esto marca una gran diferencia cuando trabajamos con imágenes grandes, video o grandes volúmenes de datos.
11.24 Relación con filtros y convoluciones
Muchas técnicas más avanzadas que veremos después también son, en esencia, operaciones matriciales. Un filtro espacial, por ejemplo, toma una pequeña región vecina de la matriz y produce un nuevo valor. Una convolución en una CNN sigue el mismo principio general, aunque con un objetivo diferente y un contexto mucho más amplio.
Por eso dominar estas operaciones básicas no es un paso menor: es el lenguaje matemático sobre el que se construye casi toda la visión computacional moderna.
11.25 Ejemplo integrado
Veamos una aplicación completa que combine acceso a cámara, recortes matriciales, coordenadas y visualización ampliada en tiempo real:
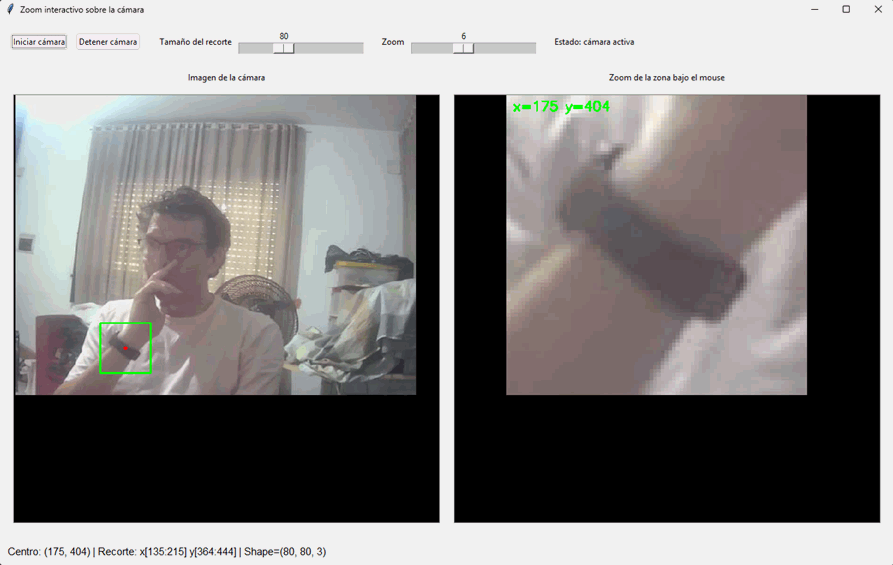
import tkinter as tk
from tkinter import ttk
import cv2
from PIL import Image, ImageTk
class ZoomCamara:
def __init__(self, root):
self.root = root
self.root.title("Zoom interactivo sobre la cámara")
self.root.geometry("1280x780")
self.cap = None
self.running = False
self.frame_actual = None
self.mouse_x_real = None
self.mouse_y_real = None
self.lado_recorte = 80
self.ancho_canvas = 580
self.alto_canvas = 430
self.img_offset_x = 0
self.img_offset_y = 0
self.img_draw_w = 0
self.img_draw_h = 0
self.crear_interfaz()
self.root.protocol("WM_DELETE_WINDOW", self.cerrar)
def crear_interfaz(self):
panel_superior = ttk.Frame(self.root, padding=10)
panel_superior.pack(fill="x")
ttk.Button(panel_superior, text="Iniciar cámara", command=self.iniciar).pack(side="left", padx=5)
ttk.Button(panel_superior, text="Detener cámara", command=self.detener).pack(side="left", padx=5)
ttk.Label(panel_superior, text="Tamaño del recorte").pack(side="left", padx=(20, 5))
self.slider_recorte = tk.Scale(panel_superior, from_=20, to=200, orient="horizontal", length=180)
self.slider_recorte.set(80)
self.slider_recorte.pack(side="left")
ttk.Label(panel_superior, text="Zoom").pack(side="left", padx=(20, 5))
self.slider_zoom = tk.Scale(panel_superior, from_=2, to=12, orient="horizontal", length=180)
self.slider_zoom.set(6)
self.slider_zoom.pack(side="left")
self.label_info = ttk.Label(panel_superior, text="Estado: detenido")
self.label_info.pack(side="left", padx=20)
panel = ttk.Frame(self.root, padding=10)
panel.pack(fill="both", expand=True)
ttk.Label(panel, text="Imagen de la cámara").grid(row=0, column=0, pady=(0, 5))
ttk.Label(panel, text="Zoom de la zona bajo el mouse").grid(row=0, column=1, pady=(0, 5))
self.canvas_camara = tk.Canvas(
panel,
width=self.ancho_canvas,
height=self.alto_canvas,
bg="black",
highlightthickness=1,
highlightbackground="gray"
)
self.canvas_camara.grid(row=1, column=0, padx=10, pady=10, sticky="nsew")
self.canvas_zoom = tk.Canvas(
panel,
width=self.ancho_canvas,
height=self.alto_canvas,
bg="black",
highlightthickness=1,
highlightbackground="gray"
)
self.canvas_zoom.grid(row=1, column=1, padx=10, pady=10, sticky="nsew")
panel.columnconfigure(0, weight=1)
panel.columnconfigure(1, weight=1)
panel.rowconfigure(1, weight=1)
self.label_datos = ttk.Label(
self.root,
text="Mueve el mouse sobre la imagen de la izquierda.",
padding=10,
font=("Arial", 11)
)
self.label_datos.pack(anchor="w")
self.canvas_camara.bind("<Motion>", self.mover_mouse)
self.canvas_camara.bind("<Leave>", self.salir_mouse)
def iniciar(self):
if self.running:
return
self.cap = cv2.VideoCapture(0)
if not self.cap.isOpened():
self.label_info.config(text="Error: no se pudo abrir la cámara")
return
self.running = True
self.label_info.config(text="Estado: cámara activa")
self.actualizar()
def detener(self):
self.running = False
if self.cap is not None:
self.cap.release()
self.cap = None
self.label_info.config(text="Estado: detenido")
def mover_mouse(self, event):
if self.frame_actual is None or self.img_draw_w <= 0 or self.img_draw_h <= 0:
return
x_rel = event.x - self.img_offset_x
y_rel = event.y - self.img_offset_y
if x_rel < 0 or y_rel < 0 or x_rel >= self.img_draw_w or y_rel >= self.img_draw_h:
self.mouse_x_real = None
self.mouse_y_real = None
return
h, w = self.frame_actual.shape[:2]
self.mouse_x_real = int(x_rel * w / self.img_draw_w)
self.mouse_y_real = int(y_rel * h / self.img_draw_h)
self.mouse_x_real = max(0, min(w - 1, self.mouse_x_real))
self.mouse_y_real = max(0, min(h - 1, self.mouse_y_real))
def salir_mouse(self, event):
self.mouse_x_real = None
self.mouse_y_real = None
def actualizar(self):
if not self.running or self.cap is None:
return
ok, frame = self.cap.read()
if not ok:
self.root.after(30, self.actualizar)
return
frame = cv2.flip(frame, 1)
self.frame_actual = frame.copy()
frame_mostrar = frame.copy()
if self.mouse_x_real is not None and self.mouse_y_real is not None:
self.actualizar_zoom()
self.dibujar_rectangulo_centrado(frame_mostrar, self.mouse_x_real, self.mouse_y_real)
else:
self.mostrar_zoom_vacio()
self.mostrar_en_canvas(frame_mostrar, self.canvas_camara, guardar_datos=True)
self.root.after(30, self.actualizar)
def dibujar_rectangulo_centrado(self, frame, cx, cy):
h, w = frame.shape[:2]
lado = self.slider_recorte.get()
mitad = lado // 2
x1 = cx - mitad
y1 = cy - mitad
x2 = x1 + lado
y2 = y1 + lado
if x1 < 0:
x1 = 0
x2 = min(w, lado)
if y1 < 0:
y1 = 0
y2 = min(h, lado)
if x2 > w:
x2 = w
x1 = max(0, w - lado)
if y2 > h:
y2 = h
y1 = max(0, h - lado)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.circle(frame, (cx, cy), 3, (0, 0, 255), -1)
def actualizar_zoom(self):
h, w = self.frame_actual.shape[:2]
lado = self.slider_recorte.get()
mitad = lado // 2
cx = self.mouse_x_real
cy = self.mouse_y_real
x1 = cx - mitad
y1 = cy - mitad
x2 = x1 + lado
y2 = y1 + lado
if x1 < 0:
x1 = 0
x2 = min(w, lado)
if y1 < 0:
y1 = 0
y2 = min(h, lado)
if x2 > w:
x2 = w
x1 = max(0, w - lado)
if y2 > h:
y2 = h
y1 = max(0, h - lado)
recorte = self.frame_actual[y1:y2, x1:x2].copy()
factor_zoom = self.slider_zoom.get()
zoom = cv2.resize(
recorte,
(recorte.shape[1] * factor_zoom, recorte.shape[0] * factor_zoom),
interpolation=cv2.INTER_NEAREST
)
cv2.putText(
zoom,
f"x={cx} y={cy}",
(10, 25),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
(0, 255, 0),
2
)
self.label_datos.config(
text=f"Centro: ({cx}, {cy}) | Recorte: x[{x1}:{x2}] y[{y1}:{y2}] | Shape={recorte.shape}"
)
self.mostrar_en_canvas(zoom, self.canvas_zoom, guardar_datos=False)
def mostrar_zoom_vacio(self):
if self.frame_actual is None:
return
self.mostrar_en_canvas(self.frame_actual, self.canvas_zoom, guardar_datos=False)
def mostrar_en_canvas(self, frame_bgr, canvas, guardar_datos=False):
frame_rgb = cv2.cvtColor(frame_bgr, cv2.COLOR_BGR2RGB)
h, w = frame_rgb.shape[:2]
canvas_w = self.ancho_canvas
canvas_h = self.alto_canvas
escala = min(canvas_w / w, canvas_h / h, 1.0)
nuevo_w = int(w * escala)
nuevo_h = int(h * escala)
offset_x = (canvas_w - nuevo_w) // 2
offset_y = (canvas_h - nuevo_h) // 2
if guardar_datos:
self.img_draw_w = nuevo_w
self.img_draw_h = nuevo_h
self.img_offset_x = offset_x
self.img_offset_y = offset_y
img_resized = cv2.resize(frame_rgb, (nuevo_w, nuevo_h), interpolation=cv2.INTER_NEAREST)
imagen_pil = Image.fromarray(img_resized)
imagen_tk = ImageTk.PhotoImage(imagen_pil)
canvas.delete("all")
canvas.create_image(offset_x, offset_y, anchor="nw", image=imagen_tk)
if canvas == self.canvas_camara:
self.tk_camara = imagen_tk
else:
self.tk_zoom = imagen_tk
def cerrar(self):
self.detener()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = ZoomCamara(root)
root.mainloop()Este ejemplo muestra cómo una idea matricial muy simple, recortar una región alrededor del cursor, puede convertirse en una aplicación visual interactiva. También refuerza la relación entre coordenadas del mouse, slicing sobre la imagen y visualización ampliada de una submatriz.
11.26 Errores comunes
Al trabajar con operaciones sobre píxeles y matrices, algunos errores frecuentes son:
- Confundir filas con columnas.
- Olvidar que el slicing puede devolver una vista.
- No controlar el tipo de dato al hacer operaciones aritméticas.
- Usar bucles innecesarios en lugar de vectorización.
- Aplicar una máscara con dimensiones incorrectas.
- No considerar el orden BGR en imágenes de OpenCV.
Evitar estos problemas mejora mucho tanto la corrección como la eficiencia del código.
11.27 Qué debes recordar de este tema
- Las imágenes pueden manipularse como matrices numéricas.
- Se puede acceder a píxeles individuales, pero en la práctica suelen ser preferibles operaciones vectorizadas.
- El slicing permite trabajar con regiones completas de forma muy eficiente.
- Las operaciones aritméticas y lógicas son fundamentales para modificar y segmentar imágenes.
- Las máscaras permiten actuar solo sobre píxeles que cumplen ciertas condiciones.
- El control del tipo de dato y del rango de valores es esencial para evitar errores.
- Estas ideas son la base de filtros, transformaciones y redes convolucionales.
11.28 Conclusión
Las operaciones sobre píxeles y matrices constituyen el núcleo matemático de la visión por computadora. Dominar estas herramientas permite entender con claridad cómo se modifica una imagen, cómo se construyen máscaras, cómo se seleccionan regiones y cómo se preparan los datos para análisis más complejos.
A medida que avancemos en el curso, veremos que esta forma de pensar se mantiene constante: incluso los algoritmos más avanzados terminan operando sobre estructuras numéricas organizadas espacialmente.
En el próximo tema estudiaremos las transformaciones geométricas de imágenes, donde empezaremos a modificar no solo los valores de los píxeles, sino también su posición dentro de la imagen.