26. Uso de modelos preentrenados
26.1 Introducción
En el tema anterior vimos la idea general del transfer learning. Ahora vamos a dar un paso más práctico: aprender a usar modelos preentrenados de manera concreta en PyTorch.
Una cosa es entender conceptualmente que un modelo puede reutilizar conocimiento previo. Otra, distinta, es saber cómo cargarlo, cómo inspeccionar su arquitectura, qué transforms necesita, cómo ejecutar inferencia y cómo adaptarlo a un problema nuevo.
En este tema nos centraremos justamente en ese uso práctico. La idea es que, al terminar, puedas tomar un modelo preentrenado de torchvision y empezar a trabajar con él de manera ordenada.
26.2 Qué es un modelo preentrenado en la práctica
En la práctica, un modelo preentrenado es una arquitectura ya definida junto con un conjunto de pesos aprendidos previamente sobre un dataset grande, normalmente ImageNet.
Eso significa que cuando lo cargamos:
- La arquitectura ya viene construida.
- Los pesos ya no son aleatorios.
- El modelo ya sabe extraer muchas características visuales útiles.
Sobre esa base, podemos hacer inferencia directa o adaptarlo a un nuevo problema.
26.3 torchvision.models
PyTorch ofrece en torchvision.models un catálogo de arquitecturas muy usadas en visión por computadora. Allí se encuentran variantes de:
- ResNet
- VGG
- DenseNet
- MobileNet
- EfficientNet
Esto facilita mucho el trabajo, porque no hace falta reconstruir estas arquitecturas manualmente para poder utilizarlas.
26.4 Cargar un modelo preentrenado
Una forma típica de cargar un modelo preentrenado es así:
from torchvision import models
weights = models.ResNet18_Weights.DEFAULT
model = models.resnet18(weights=weights)Aquí estamos diciendo que queremos una ResNet18 con pesos preentrenados por defecto. Esa línea ya deja listo el modelo para usarse.
26.5 ¿Qué son esos weights?
En versiones modernas de torchvision, los pesos preentrenados no se cargan solo como un booleano, sino mediante objetos que encapsulan más información. Ese objeto de pesos suele incluir:
- Los parámetros del modelo.
- Metadatos del entrenamiento original.
- Las transformaciones recomendadas para preprocesar imágenes.
Esto es muy útil, porque ayuda a mantener coherencia entre el modelo y la forma en que se preparan sus entradas.
26.6 Por qué importan las transforms correctas
Un modelo preentrenado no espera cualquier entrada arbitraria. Fue entrenado con imágenes procesadas de una manera específica: tamaño, normalización y formato determinados.
Si alimentamos el modelo con imágenes preparadas de forma inconsistente, el rendimiento puede degradarse mucho aunque el modelo esté bien cargado.
26.7 Obtener las transforms asociadas
Una gran ventaja de weights es que podemos pedir directamente las transformaciones sugeridas:
preprocess = weights.transforms()Esto suele devolver un pipeline listo para redimensionar, convertir a tensor y normalizar la imagen de la forma esperada por el modelo.
26.8 Inferencia básica con una imagen
Una vez cargado el modelo y las transforms, la inferencia básica sigue una lógica simple:
- Cargar la imagen.
- Aplicar las transforms.
- Agregar dimensión batch.
- Pasar el tensor por el modelo.
- Interpretar la salida.
Esto sirve tanto para clasificación directa como para verificar rápidamente que todo el pipeline funciona.
26.9 Ejemplo mínimo de inferencia
Un ejemplo básico sería:
import torch
from PIL import Image
from torchvision import models
weights = models.ResNet18_Weights.DEFAULT
model = models.resnet18(weights=weights)
model.eval()
preprocess = weights.transforms()
imagen = Image.open("foto1.jpg").convert("RGB")
entrada = preprocess(imagen).unsqueeze(0)
with torch.no_grad():
salida = model(entrada)
prediccion = salida.argmax(dim=1).item()
print("Clase predicha:", prediccion)Este código no traduce aún el índice a una etiqueta legible, pero ya muestra el flujo completo de inferencia.
26.10 El significado de la salida
En un clasificador como ResNet entrenado sobre ImageNet, la salida suele ser un vector de 1000 logits, uno por clase. El índice con mayor valor es la clase más probable según el modelo.
Es importante recordar que esos números no son directamente “nombres de clases”, sino posiciones en la lista de categorías del entrenamiento original.
26.11 Inspeccionar la arquitectura
Antes de adaptar un modelo, conviene inspeccionar su estructura. En PyTorch esto puede hacerse simplemente imprimiendo el modelo:
print(model)Esto permite ver sus bloques, capas y especialmente cómo está definida la parte final que luego podríamos querer reemplazar.
26.12 Encontrar la capa final
Cada arquitectura organiza su salida final de manera un poco distinta. En ResNet, la capa final suele estar en model.fc. En otras arquitecturas puede estar en otra ruta, como classifier.
Por eso conviene inspeccionar la arquitectura real antes de intentar modificarla.
26.13 Adaptar el modelo a nuevas clases
Si queremos reutilizar el modelo para un problema con un número diferente de clases, normalmente reemplazamos su última capa.
En ResNet18:
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, 3)Ahora la red produce 3 logits en lugar de 1000.
26.14 Congelar el backbone
Si queremos usar el modelo como extractor de características, congelamos sus capas base y entrenamos solo la nueva salida:
for param in model.parameters():
param.requires_grad = False
model.fc = torch.nn.Linear(num_features, 3)Como la capa nueva se crea después, sus parámetros quedan entrenables por defecto.
26.15 Elegir qué parámetros optimizar
Una vez congelado el backbone, lo más limpio suele ser pasar al optimizador solo los parámetros entrenables de la capa nueva:
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)Esto reduce ambigüedad y deja claro que estamos haciendo aprendizaje sobre la cabeza nueva, no sobre toda la red.
26.16 Mover el modelo al dispositivo
Como en cualquier modelo PyTorch, conviene mover tanto el modelo como los tensores de entrada al mismo dispositivo:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)Si se olvida este paso o se mezclan dispositivos, aparecerán errores en tiempo de ejecución.
26.17 Diferencia entre usarlo para inferencia y para entrenamiento
Hay dos usos muy distintos de un modelo preentrenado:
- Inferencia directa: usar el modelo tal como viene para predecir clases del dataset original.
- Adaptación: modificar su salida y reentrenarlo para un problema nuevo.
Es importante no confundir estas dos situaciones, porque cambian tanto el código como la interpretación de la salida.
26.18 Ejemplo de adaptación completa
Este ejemplo reúne carga del modelo, congelamiento y reemplazo de la última capa:
import torch
import torch.nn as nn
from torchvision import models
weights = models.ResNet18_Weights.DEFAULT
model = models.resnet18(weights=weights)
for param in model.parameters():
param.requires_grad = False
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 5)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)Aquí ya tendríamos el modelo listo para entrenarse en un problema de 5 clases.
26.19 Aplicación completa con interfaz gráfica
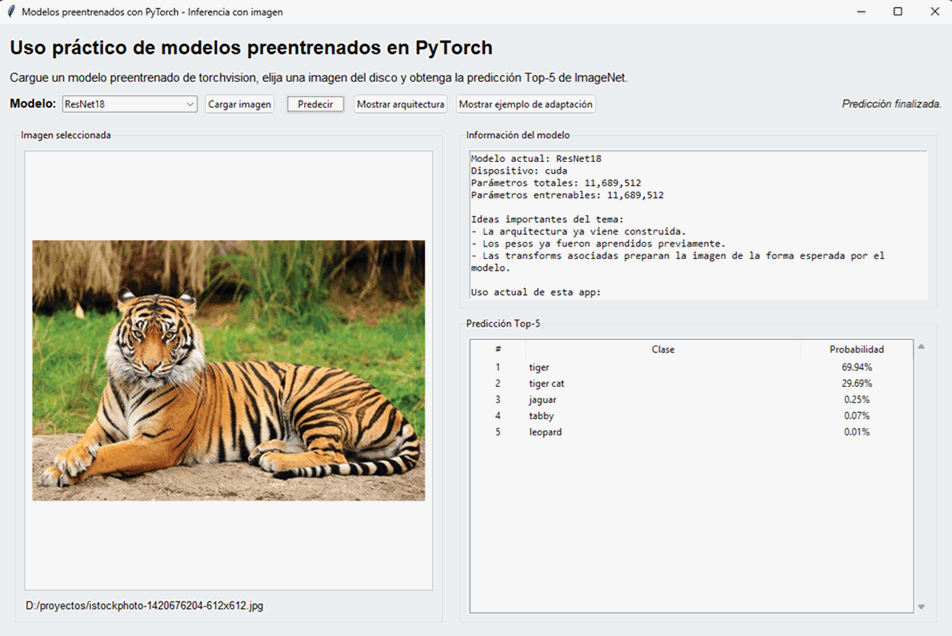
El siguiente ejemplo lleva estas ideas a una aplicación real. Permite cargar distintos modelos preentrenados de torchvision, seleccionar una imagen desde el disco y mostrar la predicción Top-5 sobre clases de ImageNet.
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from PIL import Image, ImageTk
import torch
from torchvision import models
class AplicacionModeloPreentrenado:
def __init__(self, root):
self.root = root
self.root.title("Modelos preentrenados con PyTorch - Inferencia con imagen")
self.root.geometry("1180x760")
self.root.minsize(1000, 680)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.modelos_disponibles = {
"ResNet18": self.cargar_resnet18,
"MobileNetV3 Large": self.cargar_mobilenet_v3_large,
"EfficientNet B0": self.cargar_efficientnet_b0,
}
self.nombre_modelo_actual = tk.StringVar(value="ResNet18")
self.ruta_imagen = None
self.imagen_pil = None
self.imagen_tk = None
self.modelo = None
self.weights = None
self.preprocess = None
self.categorias = []
self.crear_interfaz()
self.cargar_modelo_inicial()
# ---------------------------------------------------------
# INTERFAZ
# ---------------------------------------------------------
def crear_interfaz(self):
contenedor = ttk.Frame(self.root, padding=12)
contenedor.pack(fill="both", expand=True)
titulo = ttk.Label(
contenedor,
text="Uso práctico de modelos preentrenados en PyTorch",
font=("Arial", 18, "bold")
)
titulo.pack(anchor="w", pady=(0, 10))
descripcion = ttk.Label(
contenedor,
text=(
"Cargue un modelo preentrenado de torchvision, elija una imagen del disco y "
"obtenga la predicción Top-5 de ImageNet."
),
font=("Arial", 11)
)
descripcion.pack(anchor="w", pady=(0, 10))
barra_superior = ttk.Frame(contenedor)
barra_superior.pack(fill="x", pady=(0, 10))
ttk.Label(barra_superior, text="Modelo:", font=("Arial", 11, "bold")).pack(side="left", padx=(0, 6))
combo = ttk.Combobox(
barra_superior,
textvariable=self.nombre_modelo_actual,
values=list(self.modelos_disponibles.keys()),
state="readonly",
width=24
)
combo.pack(side="left")
combo.bind("<<ComboboxSelected>>", self.al_cambiar_modelo)
ttk.Button(barra_superior, text="Cargar imagen", command=self.seleccionar_imagen).pack(side="left", padx=8)
ttk.Button(barra_superior, text="Predecir", command=self.predecir).pack(side="left", padx=4)
ttk.Button(barra_superior, text="Mostrar arquitectura", command=self.mostrar_arquitectura).pack(side="left", padx=4)
ttk.Button(barra_superior, text="Mostrar ejemplo de adaptación", command=self.mostrar_adaptacion).pack(side="left", padx=4)
self.lbl_estado = ttk.Label(
barra_superior,
text="Listo.",
font=("Arial", 10, "italic")
)
self.lbl_estado.pack(side="right")
panel_principal = ttk.Panedwindow(contenedor, orient="horizontal")
panel_principal.pack(fill="both", expand=True)
panel_izquierdo = ttk.Frame(panel_principal, padding=8)
panel_derecho = ttk.Frame(panel_principal, padding=8)
panel_principal.add(panel_izquierdo, weight=1)
panel_principal.add(panel_derecho, weight=1)
# Panel izquierdo
marco_imagen = ttk.LabelFrame(panel_izquierdo, text="Imagen seleccionada", padding=10)
marco_imagen.pack(fill="both", expand=True)
self.canvas = tk.Canvas(marco_imagen, width=500, height=430, bg="#f4f4f4", highlightthickness=1, highlightbackground="#c0c0c0")
self.canvas.pack(fill="both", expand=True)
self.lbl_ruta = ttk.Label(marco_imagen, text="No hay imagen cargada.", font=("Arial", 10))
self.lbl_ruta.pack(anchor="w", pady=(8, 0))
# Panel derecho
marco_info = ttk.LabelFrame(panel_derecho, text="Información del modelo", padding=10)
marco_info.pack(fill="x", pady=(0, 10))
self.txt_info = tk.Text(marco_info, height=12, wrap="word", font=("Consolas", 10))
self.txt_info.pack(fill="both", expand=True)
marco_resultados = ttk.LabelFrame(panel_derecho, text="Predicción Top-5", padding=10)
marco_resultados.pack(fill="both", expand=True)
columnas = ("puesto", "clase", "probabilidad")
self.tabla = ttk.Treeview(marco_resultados, columns=columnas, show="headings", height=10)
self.tabla.heading("puesto", text="#")
self.tabla.heading("clase", text="Clase")
self.tabla.heading("probabilidad", text="Probabilidad")
self.tabla.column("puesto", width=50, anchor="center")
self.tabla.column("clase", width=320, anchor="w")
self.tabla.column("probabilidad", width=120, anchor="center")
self.tabla.pack(side="left", fill="both", expand=True)
scroll = ttk.Scrollbar(marco_resultados, orient="vertical", command=self.tabla.yview)
scroll.pack(side="right", fill="y")
self.tabla.configure(yscrollcommand=scroll.set)
# ---------------------------------------------------------
# CARGA DE MODELOS
# ---------------------------------------------------------
def cargar_modelo_inicial(self):
self.cargar_modelo(self.nombre_modelo_actual.get())
def al_cambiar_modelo(self, event=None):
self.cargar_modelo(self.nombre_modelo_actual.get())
def cargar_modelo(self, nombre_modelo):
self.lbl_estado.config(text=f"Cargando {nombre_modelo}...")
self.root.update_idletasks()
try:
self.modelo, self.weights = self.modelos_disponibles[nombre_modelo]()
self.modelo = self.modelo.to(self.device)
self.modelo.eval()
self.preprocess = self.weights.transforms()
self.categorias = self.weights.meta.get("categories", [])
self.actualizar_panel_info(nombre_modelo)
self.limpiar_resultados()
self.lbl_estado.config(text=f"Modelo cargado en {self.device}.")
except Exception as e:
self.lbl_estado.config(text="Error al cargar el modelo.")
messagebox.showerror("Error", f"No se pudo cargar el modelo:\n{e}")
def cargar_resnet18(self):
weights = models.ResNet18_Weights.DEFAULT
model = models.resnet18(weights=weights)
return model, weights
def cargar_mobilenet_v3_large(self):
weights = models.MobileNet_V3_Large_Weights.DEFAULT
model = models.mobilenet_v3_large(weights=weights)
return model, weights
def cargar_efficientnet_b0(self):
weights = models.EfficientNet_B0_Weights.DEFAULT
model = models.efficientnet_b0(weights=weights)
return model, weights
# ---------------------------------------------------------
# IMAGEN
# ---------------------------------------------------------
def seleccionar_imagen(self):
ruta = filedialog.askopenfilename(
title="Seleccionar imagen",
filetypes=[
("Archivos de imagen", "*.jpg *.jpeg *.png *.bmp *.webp"),
("Todos los archivos", "*.*")
]
)
if not ruta:
return
try:
imagen = Image.open(ruta).convert("RGB")
self.ruta_imagen = ruta
self.imagen_pil = imagen
self.lbl_ruta.config(text=ruta)
self.mostrar_imagen_en_canvas(imagen)
self.limpiar_resultados()
self.lbl_estado.config(text="Imagen cargada correctamente.")
except Exception as e:
messagebox.showerror("Error", f"No se pudo abrir la imagen:\n{e}")
def mostrar_imagen_en_canvas(self, imagen):
ancho_canvas = max(self.canvas.winfo_width(), 500)
alto_canvas = max(self.canvas.winfo_height(), 430)
copia = imagen.copy()
copia.thumbnail((ancho_canvas - 20, alto_canvas - 20))
self.imagen_tk = ImageTk.PhotoImage(copia)
self.canvas.delete("all")
x = ancho_canvas // 2
y = alto_canvas // 2
self.canvas.create_image(x, y, image=self.imagen_tk, anchor="center")
# ---------------------------------------------------------
# PREDICCIÓN
# ---------------------------------------------------------
def predecir(self):
if self.imagen_pil is None:
messagebox.showwarning("Atención", "Primero debe seleccionar una imagen.")
return
if self.modelo is None or self.preprocess is None:
messagebox.showwarning("Atención", "No hay un modelo cargado.")
return
try:
self.lbl_estado.config(text="Ejecutando inferencia...")
self.root.update_idletasks()
entrada = self.preprocess(self.imagen_pil).unsqueeze(0).to(self.device)
with torch.no_grad():
salida = self.modelo(entrada)
probabilidades = torch.softmax(salida, dim=1)
top_probabilidades, top_indices = torch.topk(probabilidades, k=5)
self.limpiar_resultados()
for i in range(5):
indice = top_indices[0, i].item()
prob = top_probabilidades[0, i].item() * 100
nombre_clase = self.categorias[indice] if indice < len(self.categorias) else f"Clase {indice}"
self.tabla.insert("", "end", values=(i + 1, nombre_clase, f"{prob:.2f}%"))
self.lbl_estado.config(text="Predicción finalizada.")
except Exception as e:
self.lbl_estado.config(text="Error durante la inferencia.")
messagebox.showerror("Error", f"No se pudo realizar la predicción:\n{e}")
# ---------------------------------------------------------
# INFORMACIÓN Y EXPLICACIONES
# ---------------------------------------------------------
def actualizar_panel_info(self, nombre_modelo):
self.txt_info.delete("1.0", tk.END)
cantidad_parametros = sum(p.numel() for p in self.modelo.parameters())
cantidad_entrenables = sum(p.numel() for p in self.modelo.parameters() if p.requires_grad)
texto = []
texto.append(f"Modelo actual: {nombre_modelo}\n")
texto.append(f"Dispositivo: {self.device}\n")
texto.append(f"Parámetros totales: {cantidad_parametros:,}\n")
texto.append(f"Parámetros entrenables: {cantidad_entrenables:,}\n\n")
texto.append("Ideas importantes del tema:\n")
texto.append("- La arquitectura ya viene construida.\n")
texto.append("- Los pesos ya fueron aprendidos previamente.\n")
texto.append("- Las transforms asociadas preparan la imagen de la forma esperada por el modelo.\n\n")
texto.append("Uso actual de esta app:\n")
texto.append("- Se carga un modelo preentrenado de torchvision.\n")
texto.append("- Se selecciona una imagen desde el disco.\n")
texto.append("- Se aplica el preprocesamiento correcto.\n")
texto.append("- Se calcula la salida y se muestran las 5 clases más probables.\n\n")
texto.append("Nota didáctica:\n")
texto.append("Estas predicciones corresponden a clases de ImageNet. Si se quisiera adaptar el modelo a un problema nuevo, habría que reemplazar la capa final y entrenarla con un dataset propio.\n")
self.txt_info.insert(tk.END, "".join(texto))
def mostrar_arquitectura(self):
if self.modelo is None:
return
ventana = tk.Toplevel(self.root)
ventana.title("Arquitectura del modelo")
ventana.geometry("900x650")
txt = tk.Text(ventana, wrap="none", font=("Consolas", 10))
txt.pack(side="left", fill="both", expand=True)
scroll_y = ttk.Scrollbar(ventana, orient="vertical", command=txt.yview)
scroll_y.pack(side="right", fill="y")
txt.configure(yscrollcommand=scroll_y.set)
txt.insert(tk.END, str(self.modelo))
txt.config(state="disabled")
def mostrar_adaptacion(self):
nombre = self.nombre_modelo_actual.get()
if nombre == "ResNet18":
codigo = '''import torch.nn as nn
from torchvision import models
weights = models.ResNet18_Weights.DEFAULT
model = models.resnet18(weights=weights)
for param in model.parameters():
param.requires_grad = False
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 3)
'''
elif nombre == "MobileNetV3 Large":
codigo = '''import torch.nn as nn
from torchvision import models
weights = models.MobileNet_V3_Large_Weights.DEFAULT
model = models.mobilenet_v3_large(weights=weights)
for param in model.parameters():
param.requires_grad = False
num_features = model.classifier[3].in_features
model.classifier[3] = nn.Linear(num_features, 3)
'''
else:
codigo = '''import torch.nn as nn
from torchvision import models
weights = models.EfficientNet_B0_Weights.DEFAULT
model = models.efficientnet_b0(weights=weights)
for param in model.parameters():
param.requires_grad = False
num_features = model.classifier[1].in_features
model.classifier[1] = nn.Linear(num_features, 3)
'''
ventana = tk.Toplevel(self.root)
ventana.title("Ejemplo de adaptación del modelo")
ventana.geometry("780x430")
ttk.Label(
ventana,
text="Ejemplo didáctico: congelar el backbone y reemplazar la capa final",
font=("Arial", 12, "bold")
).pack(anchor="w", padx=12, pady=(12, 8))
txt = tk.Text(ventana, wrap="word", font=("Consolas", 10))
txt.pack(fill="both", expand=True, padx=12, pady=(0, 12))
txt.insert(tk.END, codigo)
txt.config(state="disabled")
def limpiar_resultados(self):
for item in self.tabla.get_children():
self.tabla.delete(item)
if __name__ == "__main__":
root = tk.Tk()
app = AplicacionModeloPreentrenado(root)
root.mainloop()26.20 De dónde salen las etiquetas de las imágenes preentrenadas
Cuando un modelo como ResNet18, MobileNet o EfficientNet se carga con pesos preentrenados por defecto, normalmente esos pesos fueron aprendidos sobre ImageNet.
Eso significa que la salida del modelo corresponde a las clases del entrenamiento original, no a clases definidas por nosotros. En clasificación estándar de ImageNet, esas clases son 1000 categorías.
En torchvision, esas etiquetas no se escriben a mano dentro de nuestro programa. Vienen asociadas al objeto de pesos y pueden recuperarse con:
self.categorias = self.weights.meta.get("categories", [])Es decir, el propio objeto weights trae metadatos del entrenamiento original, incluyendo la lista de nombres de clases. Por eso luego podemos convertir un índice numérico en una etiqueta legible como "golden retriever", "tabby" o "sports car".
26.21 Partes fundamentales de la aplicación
Conviene leer este programa por bloques:
- Interfaz: construye la ventana, el selector de modelo, el área de imagen, el panel informativo y la tabla Top-5.
- Carga del modelo: según la opción elegida, crea la arquitectura, carga los pesos, obtiene las transforms y recupera las categorías de ImageNet.
- Carga de imagen: abre un archivo desde disco, lo convierte a RGB y lo muestra en el canvas.
- Predicción: aplica el preprocesamiento correcto, agrega la dimensión batch, ejecuta inferencia y calcula probabilidades con
softmax. - Presentación de resultados: toma las 5 probabilidades más altas y las muestra con su etiqueta correspondiente.
- Explicaciones auxiliares: permite inspeccionar la arquitectura del modelo y ver un ejemplo de cómo adaptarlo a otro problema.
Didácticamente, este ejemplo es muy valioso porque junta en una sola aplicación casi todos los conceptos importantes del tema: pesos preentrenados, transforms correctas, uso de metadatos, inferencia y adaptación.
26.22 Ventaja de este enfoque
Este pipeline ahorra mucho tiempo y reduce el esfuerzo de diseño. No hace falta construir una arquitectura desde cero ni esperar que el modelo aprenda desde pesos aleatorios patrones visuales básicos que otros modelos ya aprendieron antes.
Por eso, en muchísimos proyectos, usar modelos preentrenados es el punto de partida natural.
26.23 Diferencias entre arquitecturas
Aunque la lógica general es parecida, cada arquitectura tiene ciertos detalles propios:
- La capa final puede llamarse distinto.
- El tamaño de entrada preferido puede variar.
- El costo computacional cambia mucho entre modelos.
- Algunas arquitecturas son más pesadas y otras más eficientes.
Por eso conviene no memorizar solo una receta puntual, sino entender el patrón general de trabajo.
26.24 Cuándo elegir un modelo liviano
Si el despliegue final será en un dispositivo con recursos limitados, puede ser mejor usar arquitecturas como MobileNet o EfficientNet pequeñas en lugar de modelos más pesados.
No siempre el modelo más grande es la mejor decisión práctica. El uso real del sistema también importa.
26.25 Cuándo conviene una arquitectura más potente
Si el problema es complejo, hay suficiente hardware y el objetivo principal es maximizar desempeño, puede tener sentido usar modelos más expresivos como variantes mayores de ResNet o EfficientNet.
La elección del modelo preentrenado también es una decisión de ingeniería, no solo una decisión académica.
26.26 Errores comunes al usar modelos preentrenados
Algunos errores muy frecuentes son:
- No usar las transforms correctas asociadas a los pesos.
- Reemplazar mal la capa final.
- No revisar cuántas clases produce realmente el modelo.
- Intentar entrenar una arquitectura pesada sin recursos suficientes.
- Confundir inferencia directa con adaptación a nuevas clases.
26.27 Qué debes recordar de este tema
- Los modelos preentrenados pueden cargarse fácilmente desde
torchvision.models. - Los objetos
weightsno solo aportan pesos, sino también transforms recomendadas. - Conviene inspeccionar la arquitectura antes de modificarla.
- La última capa suele reemplazarse para adaptarla al nuevo número de clases.
- Congelar capas y entrenar solo la cabeza es una estrategia inicial muy común.
- El preprocesamiento correcto es tan importante como cargar el modelo correcto.
26.28 Conclusión
Usar modelos preentrenados en PyTorch es una habilidad central en visión por computadora práctica. Permite pasar muy rápido de la teoría de transfer learning a un pipeline concreto donde cargamos una arquitectura madura, reutilizamos sus pesos y la adaptamos a un problema nuevo con relativamente poco esfuerzo.
La clave no está solo en saber escribir dos o tres líneas para cargar una ResNet, sino en entender qué modelo estamos usando, qué entrada espera, qué parte conviene congelar y cómo modificar su salida de forma coherente.
En el próximo tema llevaremos esto a un caso más específico y muy clásico: la clasificación de imágenes con ResNet, donde trabajaremos sobre una arquitectura concreta de punta a punta.