34. Ejemplo completo con Kaggle, Tkinter y PyTorch
34.1 Introducción
En este tema desarrollaremos un ejemplo completo, grande y muy práctico, donde integramos varias ideas del curso en una sola aplicación real. No veremos solamente una red neuronal aislada, sino un flujo entero de trabajo: descarga del dataset, preparación de datos, entrenamiento del modelo, guardado de pesos y clasificación de nuevas imágenes desde una interfaz gráfica.
El ejemplo utiliza PyTorch para construir y entrenar la red neuronal, Tkinter para la interfaz visual del programa y Kaggle como fuente del dataset.
La aplicación clasifica imágenes en dos categorías: gato o perro. Además, el programa muestra el progreso de entrenamiento, visualiza imágenes y permite elegir un archivo desde el disco para obtener una predicción.
34.2 Qué es Kaggle
Kaggle es una plataforma muy utilizada en ciencia de datos, aprendizaje automático e inteligencia artificial. Allí podemos encontrar datasets públicos, notebooks, competencias, ejemplos de código y comunidades de usuarios que comparten soluciones y experimentos.
Para un curso como este, Kaggle resulta especialmente útil porque pone a disposición conjuntos de datos listos para usar. En vez de pasar horas buscando imágenes, organizándolas y limpiando carpetas manualmente, podemos descargar un dataset ya preparado y concentrarnos en aprender visión por computadora.
En nuestro caso usaremos el dataset salader/dogsvscats, que contiene imágenes de gatos y perros. El programa lo descargará automáticamente mediante la API de Kaggle.
34.3 Cómo crear una cuenta en Kaggle
Para usar la API de Kaggle necesitamos tener una cuenta en la plataforma. El procedimiento general es simple:
- Ingresar al sitio de Kaggle.
- Crear una cuenta nueva o iniciar sesión con una cuenta existente.
- Completar el perfil básico.
- Aceptar las condiciones de uso si la plataforma las solicita.
Una vez creada la cuenta ya podremos acceder a datasets, notebooks y también generar las credenciales necesarias para usar la API desde Python.
34.4 Qué son el nombre de usuario y el token
Para que un programa pueda descargar datasets desde Kaggle, la plataforma necesita identificar quién está realizando la operación. Para eso se usan dos datos:
- KAGGLE_USERNAME: es el nombre de usuario de tu cuenta.
- KAGGLE_KEY: es una clave privada, también llamada token o API key.
En otras palabras, el nombre de usuario indica qué cuenta realiza la operación y el token actúa como credencial secreta para autorizarla.
34.5 Cómo obtener el token y el nombre de usuario
Dentro de Kaggle, el proceso habitual es ingresar a la configuración de la cuenta y generar la API Key. Cuando hacemos esto, Kaggle suele ofrecer un archivo llamado kaggle.json. Ese archivo contiene justamente el nombre de usuario y la clave.
Su contenido tiene esta forma:
{
"username": "tu_usuario",
"key": "tu_token_privado"
}Por lo tanto, el nombre de usuario se obtiene directamente de la cuenta y el token queda dentro de ese archivo JSON que Kaggle genera al crear la API Key.
34.6 Cómo usamos las credenciales en este ejemplo
En esta aplicación, para facilitar el curso, colocamos el nombre de usuario y el token directamente dentro del programa mediante variables de entorno definidas desde Python. Esto simplifica mucho la puesta en marcha porque el alumno no necesita configurar archivos externos para comenzar.
En el código aparece así:
import os
os.environ["KAGGLE_USERNAME"] = "diegomoissetde"
os.environ["KAGGLE_KEY"] = "KGAT_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"Esto hace que la API de Kaggle encuentre las credenciales dentro del mismo proceso de Python, sin obligarnos a configurarlas previamente en el sistema operativo.
34.7 Por qué esto es cómodo para el curso pero no es lo ideal
Esta técnica es muy cómoda para explicar un ejemplo de punta a punta en un curso, porque permite que todo quede en un solo archivo y reduce la cantidad de pasos previos. Sin embargo, no es la forma más segura para un proyecto real.
Si el código se comparte, se sube a un repositorio o se publica en Internet, el token queda expuesto. Por eso, fuera de un contexto puramente didáctico, conviene guardar estas credenciales en un lugar oculto o más controlado.
34.8 Dónde conviene guardar las credenciales en una aplicación real
En proyectos reales hay varias alternativas más seguras para guardar el usuario y el token:
- Variables de entorno del sistema operativo configuradas fuera del programa.
- Archivo
kaggle.jsonen la carpeta de configuración del usuario. - Archivo
.envque no se sube al repositorio. - Archivo de configuración local ignorado por Git.
- Servicios especializados de gestión de secretos.
Cada opción tiene ventajas y desventajas, pero todas son preferibles a dejar el token escrito dentro del código fuente cuando el proyecto será distribuido o publicado.
34.9 Algunas opciones explicadas con más detalle
Las variables de entorno del sistema son una opción muy usada porque permiten que el código lea las credenciales sin escribirlas en el archivo principal del programa.
El archivo kaggle.json también es un mecanismo estándar de la propia plataforma. Muchas herramientas esperan encontrarlo en la carpeta de configuración del usuario.
Los archivos .env son comunes en muchos proyectos Python. Se usan junto con librerías que cargan esas variables al iniciar la aplicación. La ventaja es que resulta cómodo separar configuración y código.
Por último, en sistemas más profesionales o empresariales se usan gestores de secretos, que guardan claves y tokens de forma más robusta, con políticas de acceso, auditoría y rotación.
34.10 Objetivo general de la aplicación
El programa completo hará lo siguiente:
- Autenticarse en Kaggle.
- Descargar un dataset de gatos y perros.
- Extraer el archivo comprimido.
- Preparar una versión reducida del dataset.
- Cargar las imágenes con PyTorch.
- Entrenar una CNN sencilla.
- Guardar el modelo entrenado.
- Permitir seleccionar una imagen y clasificarla.
Es decir, veremos un proyecto pequeño pero completo, mucho más parecido a una aplicación real que a un ejemplo aislado de laboratorio.
34.11 Por qué descargamos un dataset grande y luego usamos una porción más pequeña
El dataset disponible en Kaggle es relativamente grande. Eso está muy bien desde el punto de vista del aprendizaje del modelo, porque disponer de muchas imágenes suele ayudar a entrenar sistemas más robustos. Pero también tiene un costo: descarga más pesada, más tiempo de preparación y mayor consumo de CPU, memoria y almacenamiento.
Como este material está pensado para un curso, debemos considerar que muchos alumnos pueden trabajar con equipos modestos. Por ese motivo, el programa descarga el dataset grande pero luego selecciona una muestra reducida de imágenes para entrenar.
Así logramos un equilibrio muy práctico: usamos un dataset real y conocido, pero limitamos la cantidad de archivos para que el entrenamiento sea más accesible en computadoras con menos recursos.
34.12 Cuántas imágenes usamos en esta versión
En el ejemplo fijamos estas constantes:
MAX_GATOS = 2000
MAX_PERROS = 2000Esto significa que tomaremos hasta 2000 imágenes de gatos y hasta 2000 imágenes de perros. En total, el conjunto reducido quedará formado por unas 4000 imágenes, siempre que el dataset tenga suficientes archivos disponibles.
Es una cantidad mucho más amigable para fines didácticos que entrenar directamente con todo el material original.
34.13 Se puede modificar la cantidad de fotos
Sí. Si deseas usar más o menos imágenes, puedes modificar directamente esas constantes dentro de la aplicación.
Por ejemplo, si tu equipo tiene muy pocos recursos podrías probar con valores menores, como 500 y 500. Si tu computadora tiene buena memoria, buen procesador o GPU disponible, podrías ampliar la cantidad para intentar lograr un mejor entrenamiento.
Este ajuste es una decisión práctica muy importante. No existe un número universalmente correcto: depende del hardware disponible, del tiempo que estemos dispuestos a esperar y del objetivo del experimento.
34.14 Código completo del ejemplo
A continuación presentamos el programa completo en un único recuadro para que sea más fácil copiarlo, leerlo y ejecutarlo.
import os
# ==========================================================
# OPCIÓN 1: CARGAR KAGGLE DIRECTAMENTE EN EL PROGRAMA
# ==========================================================
os.environ["KAGGLE_USERNAME"] = "diegomoissetde"
os.environ["KAGGLE_KEY"] = "KGAT_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
import random
import shutil
import threading
import zipfile
from pathlib import Path
import tkinter as tk
from tkinter import ttk, messagebox, filedialog
from PIL import Image, ImageTk
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
# ==========================================================
# CONFIGURACIÓN GENERAL
# ==========================================================
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
DATASET_SLUG = "salader/dogsvscats"
CARPETA_BASE = Path("cats_vs_dogs_kaggle")
CARPETA_ZIP = CARPETA_BASE / "dataset.zip"
CARPETA_EXTRAIDA = CARPETA_BASE / "extraido"
CARPETA_PREPARADA = CARPETA_BASE / "preparado"
MODELO_PATH = Path("modelo_cats_vs_dogs_reducido.pth")
BATCH_SIZE = 32
EPOCHS = 5
LEARNING_RATE = 0.001
IMAGE_SIZE = 128
MAX_GATOS = 2000
MAX_PERROS = 2000
CLASES = ["cat", "dog"]
# ==========================================================
# MODELO CNN
# ==========================================================
class RedGatosPerros(nn.Module):
def __init__(self):
super().__init__()
self.convolucional = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.clasificador = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 16 * 16, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, 2)
)
def forward(self, x):
x = self.convolucional(x)
x = self.clasificador(x)
return x
# ==========================================================
# APLICACIÓN TKINTER
# ==========================================================
class AplicacionCatsDogs:
def __init__(self, root):
self.root = root
self.root.title("Cats vs Dogs - Tkinter + PyTorch + Kaggle")
self.root.geometry("1320x820")
self.modelo = None
self.train_loader = None
self.val_loader = None
self.entrenando = False
self.imagen_tk = None
self.transformacion_dataset = transforms.Compose([
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
self.transformacion_prediccion = transforms.Compose([
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
self.crear_interfaz()
self.intentar_cargar_modelo_existente()
def crear_interfaz(self):
contenedor = ttk.Frame(self.root, padding=10)
contenedor.pack(fill="both", expand=True)
panel_izq = ttk.Frame(contenedor)
panel_izq.pack(side="left", fill="y", padx=(0, 10))
panel_der = ttk.Frame(contenedor)
panel_der.pack(side="left", fill="both", expand=True)
ttk.Label(
panel_izq,
text="Cats vs Dogs - Versión didáctica",
font=("Arial", 15, "bold")
).pack(anchor="w", pady=(0, 8))
ttk.Label(
panel_izq,
text=f"Muestra reducida: {MAX_GATOS} gatos + {MAX_PERROS} perros",
font=("Arial", 10)
).pack(anchor="w", pady=(0, 12))
self.btn_descargar = ttk.Button(
panel_izq,
text="1. Descargar dataset",
command=self.iniciar_descarga
)
self.btn_descargar.pack(fill="x", pady=4)
self.btn_preparar = ttk.Button(
panel_izq,
text="2. Preparar dataset reducido",
command=self.preparar_dataset
)
self.btn_preparar.pack(fill="x", pady=4)
self.btn_cargar = ttk.Button(
panel_izq,
text="3. Cargar datos",
command=self.cargar_datos
)
self.btn_cargar.pack(fill="x", pady=4)
self.btn_entrenar = ttk.Button(
panel_izq,
text="4. Entrenar modelo",
command=self.iniciar_entrenamiento
)
self.btn_entrenar.pack(fill="x", pady=4)
self.btn_imagen = ttk.Button(
panel_izq,
text="5. Seleccionar imagen y clasificar",
command=self.seleccionar_imagen
)
self.btn_imagen.pack(fill="x", pady=(12, 4))
self.barra = ttk.Progressbar(
panel_izq,
orient="horizontal",
mode="determinate",
length=260
)
self.barra.pack(fill="x", pady=(15, 5))
self.lbl_estado = ttk.Label(panel_izq, text="Estado: esperando acción")
self.lbl_estado.pack(anchor="w", pady=4)
self.lbl_device = ttk.Label(panel_izq, text=f"Dispositivo: {DEVICE}")
self.lbl_device.pack(anchor="w", pady=4)
self.lbl_modelo = ttk.Label(panel_izq, text="Modelo: no cargado")
self.lbl_modelo.pack(anchor="w", pady=4)
marco_info = ttk.LabelFrame(panel_izq, text="Información", padding=10)
marco_info.pack(fill="x", pady=(18, 0))
self.lbl_epoca = ttk.Label(marco_info, text="Época: -")
self.lbl_epoca.pack(anchor="w")
self.lbl_batch = ttk.Label(marco_info, text="Batch: -")
self.lbl_batch.pack(anchor="w")
self.lbl_loss = ttk.Label(marco_info, text="Loss: -")
self.lbl_loss.pack(anchor="w")
self.lbl_acc = ttk.Label(marco_info, text="Accuracy entrenamiento: -")
self.lbl_acc.pack(anchor="w")
self.lbl_val = ttk.Label(marco_info, text="Accuracy validación: -")
self.lbl_val.pack(anchor="w")
self.lbl_pred = ttk.Label(
panel_izq,
text="Predicción: -",
font=("Arial", 12, "bold")
)
self.lbl_pred.pack(anchor="w", pady=(20, 4))
self.lbl_prob = ttk.Label(panel_izq, text="Probabilidad: -")
self.lbl_prob.pack(anchor="w", pady=4)
marco_imagen = ttk.LabelFrame(panel_der, text="Visualización", padding=10)
marco_imagen.pack(fill="both", expand=True)
self.canvas = tk.Canvas(marco_imagen, width=780, height=680, bg="black")
self.canvas.pack(fill="both", expand=True)
self.lbl_imagen = ttk.Label(
panel_der,
text="Imagen actual: -",
font=("Arial", 11, "bold")
)
self.lbl_imagen.pack(pady=8)
def actualizar_estado(self, texto):
self.root.after(0, lambda: self.lbl_estado.config(text=f"Estado: {texto}"))
def actualizar_barra(self, valor, maximo=100):
def _actualizar():
self.barra["maximum"] = maximo
self.barra["value"] = valor
self.root.after(0, _actualizar)
def mostrar_pil_en_canvas(self, imagen_pil, texto_label):
ancho_canvas = self.canvas.winfo_width()
alto_canvas = self.canvas.winfo_height()
if ancho_canvas < 10:
ancho_canvas = 780
if alto_canvas < 10:
alto_canvas = 680
copia = imagen_pil.copy()
copia.thumbnail((ancho_canvas - 20, alto_canvas - 20))
self.imagen_tk = ImageTk.PhotoImage(copia)
def _dibujar():
self.canvas.delete("all")
self.canvas.create_image(
ancho_canvas // 2,
alto_canvas // 2,
image=self.imagen_tk
)
self.lbl_imagen.config(text=texto_label)
self.root.after(0, _dibujar)
def mostrar_imagen_tensor(self, tensor, etiqueta_real):
imagen = tensor.detach().cpu()
media = torch.tensor([0.5, 0.5, 0.5]).view(3, 1, 1)
desv = torch.tensor([0.5, 0.5, 0.5]).view(3, 1, 1)
imagen = imagen * desv + media
imagen = torch.clamp(imagen, 0, 1)
pil = transforms.ToPILImage()(imagen)
self.mostrar_pil_en_canvas(pil, f"Imagen actual: {CLASES[etiqueta_real]}")
def autenticar_kaggle(self):
from kaggle.api.kaggle_api_extended import KaggleApi
username = os.environ.get("KAGGLE_USERNAME")
key = os.environ.get("KAGGLE_KEY")
if not username or not key:
raise RuntimeError(
"No se encontraron KAGGLE_USERNAME y KAGGLE_KEY dentro del programa."
)
api = KaggleApi()
api.authenticate()
return api
def dataset_ya_preparado(self):
carpeta_cat = CARPETA_PREPARADA / "cat"
carpeta_dog = CARPETA_PREPARADA / "dog"
if not carpeta_cat.exists() or not carpeta_dog.exists():
return False
cantidad_cat = len(list(carpeta_cat.glob("*.jpg")))
cantidad_dog = len(list(carpeta_dog.glob("*.jpg")))
return cantidad_cat >= 1 and cantidad_dog >= 1
def intentar_cargar_modelo_existente(self):
if MODELO_PATH.exists():
try:
self.modelo = RedGatosPerros().to(DEVICE)
self.modelo.load_state_dict(torch.load(MODELO_PATH, map_location=DEVICE))
self.modelo.eval()
self.lbl_modelo.config(text=f"Modelo: cargado desde {MODELO_PATH.name}")
self.actualizar_estado("modelo existente cargado")
except Exception:
self.lbl_modelo.config(text="Modelo: encontrado pero no se pudo cargar")
def iniciar_descarga(self):
hilo = threading.Thread(target=self.descargar_dataset, daemon=True)
hilo.start()
def descargar_dataset(self):
try:
CARPETA_BASE.mkdir(exist_ok=True)
if CARPETA_ZIP.exists():
self.actualizar_estado("el zip ya existe, no se vuelve a descargar")
messagebox.showinfo(
"Descarga",
f"El archivo ya existe:\n{CARPETA_ZIP}\n\nNo se volvió a descargar."
)
return
if self.dataset_ya_preparado():
self.actualizar_estado("el dataset ya está preparado")
messagebox.showinfo(
"Descarga",
"El dataset reducido ya está preparado.\nNo hace falta volver a descargarlo."
)
return
self.actualizar_estado("descargando dataset desde Kaggle...")
self.actualizar_barra(0, 100)
api = self.autenticar_kaggle()
self.actualizar_barra(15, 100)
api.dataset_download_files(
DATASET_SLUG,
path=str(CARPETA_BASE),
unzip=False,
quiet=False
)
archivos_zip = list(CARPETA_BASE.glob("*.zip"))
if not archivos_zip:
raise RuntimeError("No se encontró el archivo zip descargado.")
archivo_bajado = archivos_zip[0]
if archivo_bajado != CARPETA_ZIP:
if CARPETA_ZIP.exists():
CARPETA_ZIP.unlink()
archivo_bajado.rename(CARPETA_ZIP)
self.actualizar_barra(100, 100)
self.actualizar_estado("dataset descargado correctamente")
messagebox.showinfo("Descarga", "El dataset se descargó correctamente.")
except Exception as e:
self.actualizar_estado("error en la descarga")
messagebox.showerror("Error", f"No se pudo descargar el dataset.\n\n{e}")
def preparar_dataset(self):
hilo = threading.Thread(target=self._preparar_dataset_hilo, daemon=True)
hilo.start()
def _preparar_dataset_hilo(self):
try:
if self.dataset_ya_preparado():
self.actualizar_estado("dataset reducido ya preparado")
messagebox.showinfo(
"Preparación",
"El dataset reducido ya existe.\nNo se volvió a preparar."
)
return
if not CARPETA_ZIP.exists():
raise RuntimeError("Primero debes descargar el dataset.")
self.actualizar_estado("extrayendo zip...")
self.actualizar_barra(0, 100)
if CARPETA_EXTRAIDA.exists():
shutil.rmtree(CARPETA_EXTRAIDA)
CARPETA_EXTRAIDA.mkdir(parents=True, exist_ok=True)
with zipfile.ZipFile(CARPETA_ZIP, "r") as archivo_zip:
archivo_zip.extractall(CARPETA_EXTRAIDA)
self.actualizar_barra(20, 100)
self.actualizar_estado("buscando imágenes de gatos y perros...")
if CARPETA_PREPARADA.exists():
shutil.rmtree(CARPETA_PREPARADA)
(CARPETA_PREPARADA / "cat").mkdir(parents=True, exist_ok=True)
(CARPETA_PREPARADA / "dog").mkdir(parents=True, exist_ok=True)
archivos_gatos = []
archivos_perros = []
for archivo in CARPETA_EXTRAIDA.rglob("*.jpg"):
nombre = archivo.name.lower()
if nombre.startswith("cat"):
archivos_gatos.append(archivo)
elif nombre.startswith("dog"):
archivos_perros.append(archivo)
if not archivos_gatos or not archivos_perros:
raise RuntimeError("No se encontraron imágenes de gatos o perros.")
random.shuffle(archivos_gatos)
random.shuffle(archivos_perros)
archivos_gatos = archivos_gatos[:MAX_GATOS]
archivos_perros = archivos_perros[:MAX_PERROS]
total_a_copiar = len(archivos_gatos) + len(archivos_perros)
copiados = 0
self.actualizar_estado("copiando gatos...")
for archivo in archivos_gatos:
destino = CARPETA_PREPARADA / "cat" / archivo.name
shutil.copy2(archivo, destino)
copiados += 1
self.actualizar_barra(copiados, total_a_copiar)
self.actualizar_estado("copiando perros...")
for archivo in archivos_perros:
destino = CARPETA_PREPARADA / "dog" / archivo.name
shutil.copy2(archivo, destino)
copiados += 1
self.actualizar_barra(copiados, total_a_copiar)
self.actualizar_estado("dataset reducido preparado")
messagebox.showinfo(
"Preparación",
f"Dataset reducido listo.\n\n"
f"Gatos: {len(archivos_gatos)}\n"
f"Perros: {len(archivos_perros)}\n"
f"Total: {total_a_copiar}"
)
except Exception as e:
self.actualizar_estado("error al preparar dataset")
messagebox.showerror("Error", f"No se pudo preparar el dataset.\n\n{e}")
def cargar_datos(self):
try:
if not self.dataset_ya_preparado():
raise RuntimeError("Primero debes preparar el dataset reducido.")
self.actualizar_estado("cargando datos en PyTorch...")
dataset_completo = datasets.ImageFolder(
root=str(CARPETA_PREPARADA),
transform=self.transformacion_dataset
)
cantidad_total = len(dataset_completo)
cantidad_train = int(cantidad_total * 0.8)
cantidad_val = cantidad_total - cantidad_train
generador = torch.Generator().manual_seed(42)
train_dataset, val_dataset = random_split(
dataset_completo,
[cantidad_train, cantidad_val],
generator=generador
)
self.train_loader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
self.val_loader = DataLoader(
val_dataset,
batch_size=BATCH_SIZE,
shuffle=False
)
self.actualizar_estado(f"datos cargados: {cantidad_total} imágenes")
messagebox.showinfo(
"Carga exitosa",
f"Total: {cantidad_total}\n"
f"Entrenamiento: {cantidad_train}\n"
f"Validación: {cantidad_val}"
)
except Exception as e:
self.actualizar_estado("error al cargar datos")
messagebox.showerror("Error", str(e))
def iniciar_entrenamiento(self):
if self.train_loader is None or self.val_loader is None:
messagebox.showwarning("Aviso", "Primero debes cargar los datos.")
return
if self.entrenando:
return
self.entrenando = True
hilo = threading.Thread(target=self.entrenar_modelo, daemon=True)
hilo.start()
def evaluar_validacion(self):
self.modelo.eval()
correctos = 0
total = 0
with torch.no_grad():
for imagenes, etiquetas in self.val_loader:
imagenes = imagenes.to(DEVICE)
etiquetas = etiquetas.to(DEVICE)
salidas = self.modelo(imagenes)
predicciones = torch.argmax(salidas, dim=1)
total += etiquetas.size(0)
correctos += (predicciones == etiquetas).sum().item()
if total == 0:
return 0.0
return 100.0 * correctos / total
def entrenar_modelo(self):
try:
self.modelo = RedGatosPerros().to(DEVICE)
criterio = nn.CrossEntropyLoss()
optimizador = optim.Adam(self.modelo.parameters(), lr=LEARNING_RATE)
total_batches = len(self.train_loader)
self.actualizar_barra(0, total_batches * EPOCHS)
for epoca in range(EPOCHS):
self.modelo.train()
correctos = 0
total = 0
loss_acumulada = 0.0
for indice_batch, (imagenes, etiquetas) in enumerate(self.train_loader, start=1):
imagenes = imagenes.to(DEVICE)
etiquetas = etiquetas.to(DEVICE)
optimizador.zero_grad()
salidas = self.modelo(imagenes)
loss = criterio(salidas, etiquetas)
loss.backward()
optimizador.step()
loss_acumulada += loss.item()
predicciones = torch.argmax(salidas, dim=1)
total += etiquetas.size(0)
correctos += (predicciones == etiquetas).sum().item()
acc_actual = 100.0 * correctos / total if total > 0 else 0.0
indice_mostrar = random.randint(0, imagenes.size(0) - 1)
self.mostrar_imagen_tensor(
imagenes[indice_mostrar],
etiquetas[indice_mostrar].item()
)
progreso_global = epoca * total_batches + indice_batch
self.actualizar_barra(progreso_global, total_batches * EPOCHS)
self.root.after(
0,
lambda e=epoca + 1: self.lbl_epoca.config(text=f"Época: {e}/{EPOCHS}")
)
self.root.after(
0,
lambda b=indice_batch, tb=total_batches: self.lbl_batch.config(text=f"Batch: {b}/{tb}")
)
self.root.after(
0,
lambda l=loss.item(): self.lbl_loss.config(text=f"Loss: {l:.4f}")
)
self.root.after(
0,
lambda a=acc_actual: self.lbl_acc.config(text=f"Accuracy entrenamiento: {a:.2f}%")
)
acc_val = self.evaluar_validacion()
loss_promedio = loss_acumulada / total_batches
self.root.after(
0,
lambda v=acc_val: self.lbl_val.config(text=f"Accuracy validación: {v:.2f}%")
)
self.actualizar_estado(
f"época {epoca + 1} finalizada - loss {loss_promedio:.4f} - val {acc_val:.2f}%"
)
torch.save(self.modelo.state_dict(), MODELO_PATH)
self.modelo.eval()
self.root.after(
0,
lambda: self.lbl_modelo.config(text=f"Modelo: guardado en {MODELO_PATH.name}")
)
self.actualizar_estado("entrenamiento finalizado")
messagebox.showinfo(
"Entrenamiento finalizado",
f"Modelo guardado en:\n{MODELO_PATH}"
)
except Exception as e:
messagebox.showerror("Error en entrenamiento", str(e))
self.actualizar_estado("error en entrenamiento")
finally:
self.entrenando = False
def seleccionar_imagen(self):
ruta = filedialog.askopenfilename(
title="Seleccionar imagen",
filetypes=[
("Imágenes", "*.jpg *.jpeg *.png *.bmp *.webp"),
("Todos los archivos", "*.*")
]
)
if not ruta:
return
try:
if self.modelo is None:
if MODELO_PATH.exists():
self.intentar_cargar_modelo_existente()
if self.modelo is None:
raise RuntimeError(
"No hay modelo cargado.\n"
"Primero entrena el modelo o asegúrate de que exista el archivo guardado."
)
imagen = Image.open(ruta).convert("RGB")
self.mostrar_pil_en_canvas(imagen, f"Imagen seleccionada: {Path(ruta).name}")
tensor = self.transformacion_prediccion(imagen).unsqueeze(0).to(DEVICE)
self.modelo.eval()
with torch.no_grad():
salida = self.modelo(tensor)
probabilidades = torch.softmax(salida, dim=1)[0]
indice = int(torch.argmax(probabilidades).item())
prob = float(probabilidades[indice].item()) * 100.0
clase = CLASES[indice]
self.lbl_pred.config(text=f"Predicción: {clase}")
self.lbl_prob.config(text=f"Probabilidad: {prob:.2f}%")
self.actualizar_estado("predicción realizada")
except Exception as e:
messagebox.showerror("Error", f"No se pudo clasificar la imagen.\n\n{e}")
# ==========================================================
# PROGRAMA PRINCIPAL
# ==========================================================
if __name__ == "__main__":
root = tk.Tk()
app = AplicacionCatsDogs(root)
root.mainloop()34.19 Bibliotecas que intervienen
El script utiliza varias bibliotecas, y cada una cumple un rol preciso:
ospara manejar variables de entorno.random,shutil,threadingyzipfilepara tareas auxiliares del dataset.pathlib.Pathpara construir rutas de forma más clara.tkinteryttkpara la interfaz gráfica.PILpara abrir y mostrar imágenes.torchytorchvisionpara toda la parte de Deep Learning.
Esta mezcla muestra algo importante: en aplicaciones reales de inteligencia artificial no basta con saber definir una red. También necesitamos organizar archivos, interfaz, descarga de datos y manejo de errores.
34.20 Configuración general del proyecto
Después de los imports aparece un bloque de configuración donde se definen rutas, hiperparámetros y opciones principales del programa.
Allí se decide, por ejemplo, si usamos CPU o GPU, cuál es el nombre del dataset en Kaggle, dónde se guardará el archivo ZIP, dónde se extraerán las imágenes, dónde se ubicará el modelo entrenado y qué tamaño tendrán las imágenes.
Separar estos valores en constantes hace que el programa sea más fácil de leer y modificar.
34.21 El dispositivo de ejecución
Esta línea detecta automáticamente si hay una GPU compatible:
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")Si CUDA está disponible, el programa intentará aprovechar la GPU. Si no lo está, trabajará con CPU. Esto permite que el mismo ejemplo funcione en equipos muy distintos sin necesidad de cambiar el código principal.
34.22 Rutas del dataset y del modelo
La aplicación define varias carpetas para ordenar el trabajo:
CARPETA_BASEcontiene todo el proyecto descargado.CARPETA_ZIPguarda el dataset comprimido.CARPETA_EXTRAIDAcontiene los archivos luego de descomprimir.CARPETA_PREPARADAcontiene la muestra reducida y ordenada.MODELO_PATHguarda el archivo de pesos entrenados.
Esta organización evita mezclar material bruto con datos preparados y con resultados del entrenamiento.
34.23 La CNN que vamos a entrenar
La red RedGatosPerros es una CNN pequeña, pensada para fines didácticos. Tiene tres bloques convolucionales, cada uno seguido por una activación ReLU y una reducción espacial con MaxPool2d.
Luego, la salida pasa a una parte clasificadora formada por una capa Flatten, una capa lineal intermedia, una activación ReLU, un Dropout y finalmente una capa lineal de salida con dos neuronas, una por cada clase.
No es una arquitectura grande ni de última generación, pero es suficiente para mostrar un pipeline completo sin que el código se vuelva demasiado complejo.
34.24 Por qué el tamaño de entrada es 128 x 128
En este ejemplo redimensionamos todas las imágenes a 128 x 128. Este tamaño es más pequeño que el usado en muchos modelos clásicos, pero reduce bastante el consumo de memoria y acelera el entrenamiento.
Otra vez aparece una decisión práctica. Elegimos un valor razonable para un curso y para equipos que pueden no disponer de mucho hardware. Si quisiéramos más detalle visual, podríamos aumentar este tamaño, pero a costa de más recursos.
34.25 Transformaciones aplicadas a las imágenes
Tanto para el dataset como para la predicción usamos tres transformaciones principales:
Resize((IMAGE_SIZE, IMAGE_SIZE))para igualar tamaño.ToTensor()para convertir la imagen en tensor.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))para normalizar canales RGB.
Es importante que la predicción use el mismo tipo de preprocesamiento que el entrenamiento. Si no mantenemos esa consistencia, el modelo puede recibir entradas distribuidas de manera distinta a las que vio al entrenar y su rendimiento puede empeorar.
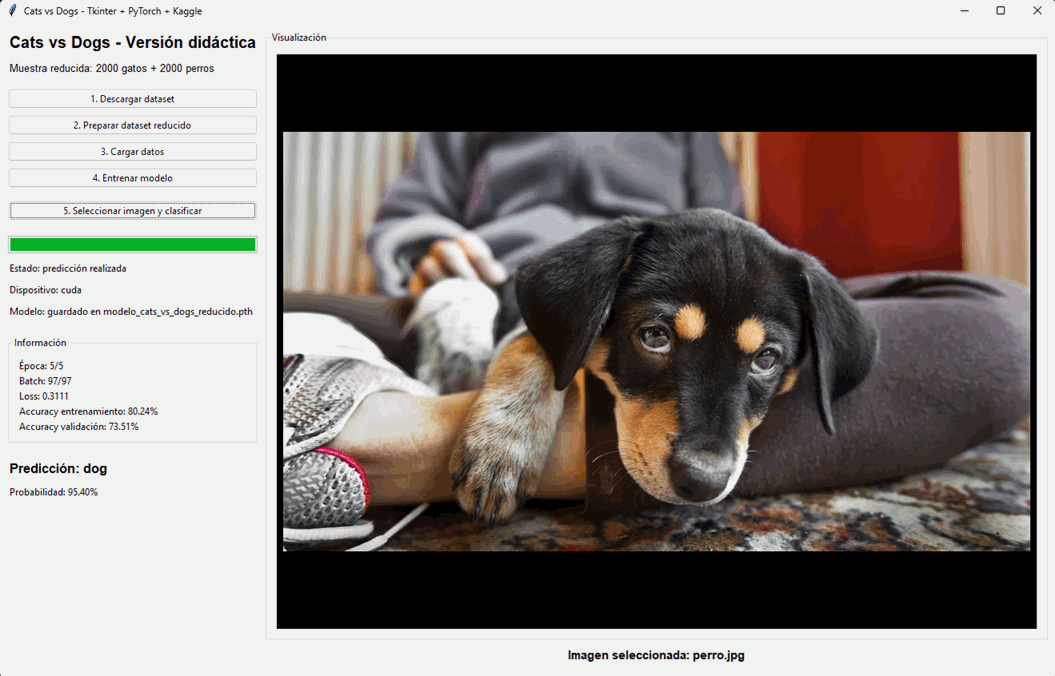
34.26 La interfaz gráfica
El método crear_interfaz arma la ventana principal. A la izquierda tenemos botones y etiquetas informativas. A la derecha aparece un área de visualización de imágenes.
Los botones siguen el flujo lógico del proyecto:
- Descargar dataset.
- Preparar dataset reducido.
- Cargar datos.
- Entrenar modelo.
- Seleccionar imagen y clasificar.
Esto vuelve la aplicación muy clara para quien está aprendiendo, porque cada paso del pipeline aparece también como una acción visible en la interfaz.
34.27 Por qué usamos hilos
Las operaciones de descarga, preparación del dataset y entrenamiento pueden tardar bastante tiempo. Si se ejecutaran directamente en el hilo principal de Tkinter, la interfaz quedaría congelada.
Por eso usamos threading.Thread en varias partes del programa. Así las tareas largas corren en segundo plano y la ventana puede seguir respondiendo, actualizando la barra de progreso y mostrando mensajes de estado.
34.28 Autenticación con Kaggle
El método autenticar_kaggle importa la clase KaggleApi, lee las variables de entorno y verifica que realmente existan. Si faltan, lanza un error claro.
Luego crea el objeto API y ejecuta authenticate(). A partir de ese momento el programa ya puede pedirle a Kaggle la descarga del dataset.
Esta parte muestra una práctica útil: validar las credenciales antes de avanzar, para no continuar el flujo con una configuración incompleta.
34.29 Descarga del dataset
La función descargar_dataset se encarga de bajar el archivo ZIP desde Kaggle. Antes de hacerlo, revisa si el ZIP ya existe o si el dataset reducido ya fue preparado. Si alguna de esas condiciones se cumple, evita repetir trabajo innecesario.
Esto es importante porque descargar siempre desde cero sería incómodo y consumiría tiempo y ancho de banda sin necesidad.
La descarga real se hace con:
api.dataset_download_files(
DATASET_SLUG,
path=str(CARPETA_BASE),
unzip=False,
quiet=False
)Observa que aquí todavía no se descomprime el archivo. Solo se descarga el ZIP.
34.30 Preparación del dataset reducido
Una vez descargado el ZIP, el programa lo extrae y recorre todos los archivos .jpg. Luego identifica cuáles corresponden a gatos y cuáles a perros analizando el comienzo del nombre del archivo.
Después mezcla ambas listas aleatoriamente con random.shuffle y toma solo una porción de cada una según los límites configurados en MAX_GATOS y MAX_PERROS.
Finalmente copia esas imágenes seleccionadas a una carpeta nueva con esta estructura:
preparado/
cat/
dog/Esta organización es ideal para usar luego ImageFolder.
34.31 Ventaja didáctica de esta preparación
Este paso tiene mucho valor pedagógico porque enseña algo que en proyectos reales ocurre constantemente: el dataset original no siempre está listo para entrenar de la manera exacta que necesitamos.
A veces debemos descargar, descomprimir, reorganizar carpetas, elegir una muestra, limpiar archivos y adaptar nombres. Este ejemplo muestra justamente esa parte del trabajo, que muchas veces se omite en ejercicios demasiado simplificados.
34.32 Carga de datos con ImageFolder
Luego usamos datasets.ImageFolder para leer las imágenes desde la carpeta preparada. Como las subcarpetas se llaman cat y dog, PyTorch genera automáticamente las clases correspondientes.
Después dividimos el dataset en entrenamiento y validación usando random_split. En este ejemplo empleamos un 80% para entrenamiento y un 20% para validación.
También fijamos una semilla con manual_seed(42) para que la partición sea reproducible.
34.33 DataLoaders
Con los subconjuntos ya generados, creamos dos DataLoader:
- Uno para entrenamiento, con
shuffle=True. - Otro para validación, con
shuffle=False.
Esto sigue una práctica clásica. Durante entrenamiento conviene mezclar los datos. En validación, en cambio, no es necesario.
34.34 Entrenamiento del modelo
El entrenamiento comienza creando una instancia nueva de la red y enviándola al dispositivo adecuado. Luego se define la función de pérdida CrossEntropyLoss y el optimizador Adam.
Durante cada época, el programa recorre los batches, calcula salidas, obtiene la pérdida, hace backpropagation y actualiza los pesos. A medida que avanza, también calcula métricas de accuracy y actualiza la interfaz.
Esto convierte al ejemplo en una herramienta bastante visual para comprender qué está ocurriendo durante el aprendizaje.
34.35 Visualización durante el entrenamiento
Un detalle interesante es que en cada batch se elige una imagen aleatoria del lote y se muestra en el canvas. De este modo, mientras el modelo entrena, el usuario puede ver ejemplos concretos de las imágenes que están pasando por el pipeline.
Además, la aplicación informa época, batch, loss, accuracy de entrenamiento y accuracy de validación. Esto ayuda a relacionar los números del entrenamiento con imágenes reales del dataset.
34.36 Evaluación sobre validación
Al final de cada época, el método evaluar_validacion recorre el conjunto de validación con torch.no_grad(), calcula predicciones y obtiene el porcentaje de aciertos.
Esta métrica permite tener una referencia más confiable del rendimiento del modelo que la accuracy de entrenamiento, ya que se mide sobre imágenes no usadas para ajustar los pesos.
34.37 Guardado del modelo
Cuando termina el entrenamiento, el programa guarda los pesos con:
torch.save(self.modelo.state_dict(), MODELO_PATH)El archivo resultante podrá reutilizarse más adelante sin necesidad de volver a entrenar desde cero. La propia aplicación, al iniciarse, intenta cargar automáticamente ese modelo si ya existe.
34.38 Clasificación de una imagen nueva
Una vez entrenado el modelo, el botón de selección de imagen permite abrir un archivo del disco. El programa lo convierte a RGB, lo muestra en la interfaz, aplica las transformaciones correspondientes, agrega la dimensión batch y ejecuta la red.
Luego calcula las probabilidades con softmax, identifica la clase más probable y muestra tanto la predicción como el porcentaje asociado.
Este es el paso final del pipeline: pasar de un modelo entrenado a una aplicación que responde sobre imágenes nuevas elegidas por el usuario.
34.39 Qué ventajas tiene este ejemplo para aprender
Este caso práctico es especialmente útil porque reúne en un solo programa varios temas del curso:
- Gestión de datasets reales.
- Uso de Kaggle como fuente de datos.
- Preparación y reducción de conjuntos de imágenes.
- Entrenamiento supervisado con PyTorch.
- Validación del modelo.
- Persistencia de pesos.
- Inferencia desde una interfaz gráfica.
Es decir, ya no estamos viendo fragmentos sueltos, sino un flujo integrado de principio a fin.
34.40 Qué limitaciones tiene
Como todo ejemplo didáctico, esta aplicación también simplifica varias cosas. La arquitectura es modesta, la evaluación usa solo entrenamiento y validación, no incorporamos técnicas avanzadas de aumento de datos y la seguridad de las credenciales está relajada para favorecer la claridad del curso.
Eso no invalida el ejemplo. Al contrario, lo vuelve más accesible. Pero es importante entender qué partes son didácticas y cuáles convendría reforzar en un proyecto serio.
34.41 Mejoras posibles
Si quisieras extender esta aplicación, algunas mejoras razonables serían:
- Guardar también métricas históricas por época.
- Agregar aumentos de datos para entrenamiento.
- Usar una arquitectura preentrenada.
- Separar un conjunto de test final.
- Ocultar las credenciales en un archivo externo o en variables del sistema.
- Permitir modificar desde la interfaz la cantidad de imágenes a usar.
Estas extensiones acercarían el ejemplo a una aplicación más robusta.
34.42 Qué debes recordar de este tema
- Kaggle es una plataforma muy útil para conseguir datasets reales de aprendizaje automático.
- Para usar la API de Kaggle se necesitan un nombre de usuario y un token.
- En este curso colocamos esas credenciales dentro del programa para simplificar el ejemplo, pero en una aplicación real conviene ocultarlas.
- El programa descarga un dataset grande y luego toma una muestra más pequeña para que el entrenamiento sea viable en equipos con menos recursos.
- La cantidad de imágenes puede modificarse ajustando las constantes del programa.
- El ejemplo integra descarga, preparación de datos, entrenamiento, validación, guardado del modelo e inferencia final.
34.43 Conclusión
Este tema muestra un caso práctico mucho más cercano a un proyecto real que a un ejemplo mínimo de laboratorio. Aprendimos qué es Kaggle, cómo obtener las credenciales necesarias para usar su API y por qué en el curso decidimos colocarlas dentro del programa para simplificar la experiencia de aprendizaje.
También vimos que trabajar con datasets reales implica tomar decisiones prácticas. Aunque descargamos un conjunto grande de imágenes, luego usamos una versión reducida para que el entrenamiento sea posible incluso en computadoras modestas. Esa cantidad puede ajustarse según las necesidades y recursos del usuario.
Finalmente, integramos todo en una aplicación con interfaz gráfica que descarga datos, los prepara, entrena una CNN y clasifica nuevas imágenes. Esa mirada integrada es fundamental para comprender cómo se construyen soluciones completas de visión por computadora.